What Are the 5 Key Stages of the Resilience Lifecycle Framework?

Jigar Mistry

Resilience Lifecycle Framework model for business continuity
A few minutes of downtime can cost an organization thousands, if not millions, of dollars. In fact, sudden outages and downtime result in enterprises incurring annual losses of $400 billion.
Digital resilience is no longer a luxury, it’s a matter of life and death for modern businesses. Disruptions like cyber attacks, system failures, or global crises don’t ask permission, and they don’t wait.
Most companies still treat resilience as a reactive patchwork, focusing on firefighting instead of embedding resilience into their core operations. That mindset leads to broken trust, damaged reputation, and unbearable costs when adversity hits.
The solution? Embrace a structured approach of a resilience lifecycle framework. It’s a step-by-step process that enables businesses to build systems capable of anticipating, withstanding, absorbing, recovering from, and then adapting in the face of disruption.
This article focuses on key stages of the resiliency lifecycle framework and how you can leverage them to ensure proactive actions to reduce downtime.
What Is the Resilience Lifecycle Framework?
Resilience Lifecycle Framework is a structured, continuous approach developed by AWS to help organizations systematically build and improve their ability to resist, recover from, and learn from disruptions.
AWS defines resilience as “the ability of an application to resist or recover from disruptions, including those related to infrastructure, dependent services, misconfigurations, and transient network issues”.
For software-driven companies, this means planning for unexpected events so that the app, platform, or service remains online, secure, and reliable in situations of extreme stress.
Why it matters for software and tech teams:
- Early recognition of risks within the software lifecycle
- Supports scalable, fault-tolerant architecture
(a cloud-native, microservices, auto-scaling model) - In line with DevOps, agile, and CI/CD workflows
- Protects uptime, data, and customer trust
This extends beyond IT concerns. It becomes a business strategy. Innovations can be developed faster, recovery can occur sooner, and the user experience can improve and become more dependable with resilience built into the technology stack.
Let’s understand the five key stages of the Resilience Lifecycle Framework.
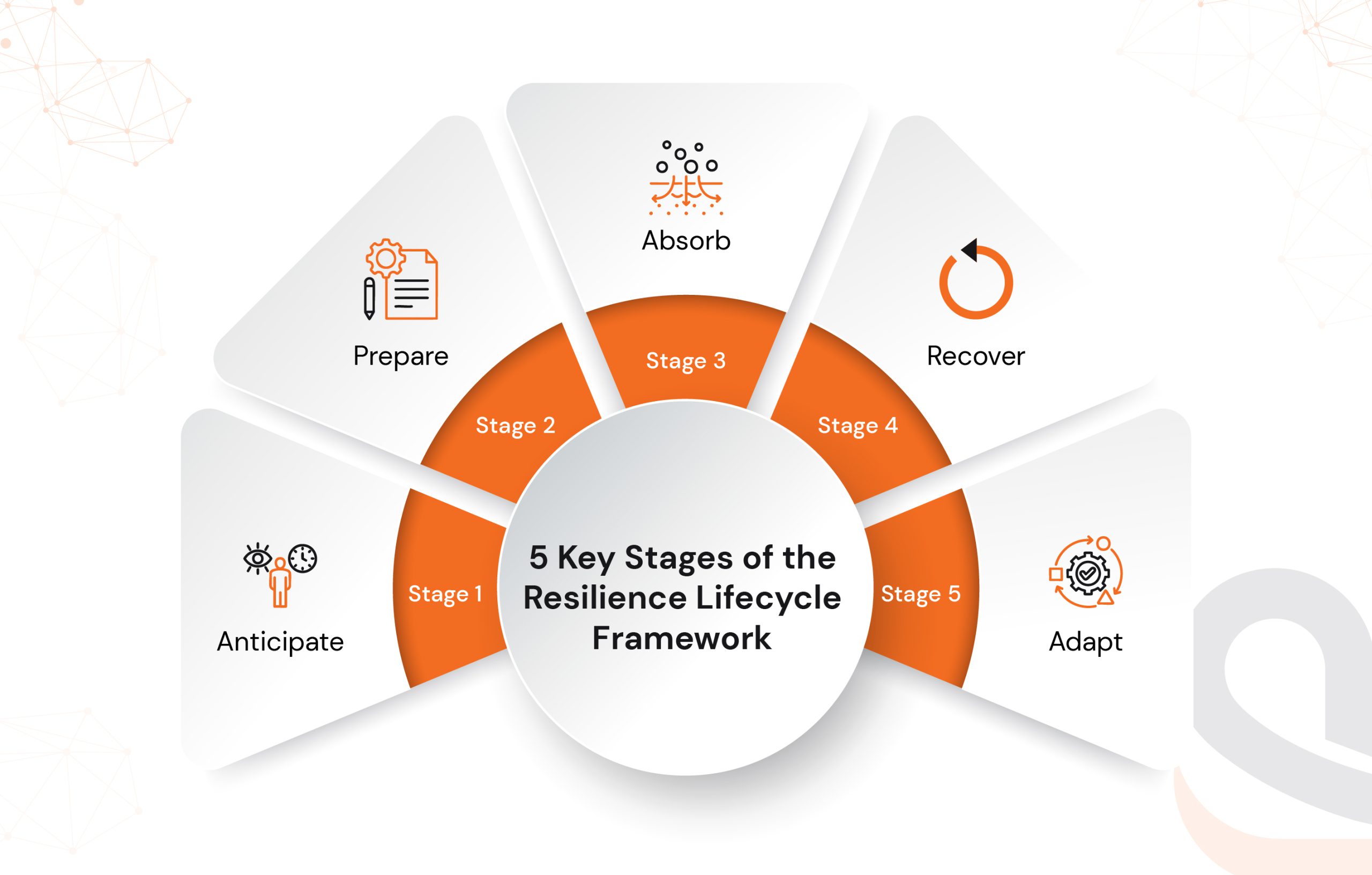
Stage 1: Anticipate: Building Awareness Before Disruption Hits
Anticipating is the first and perhaps most fundamental element of the Resilience Lifecycle Framework. At this stage, companies are attempting to identify risks, weaknesses, and blind spots in their systems before they become significant disruptions.
The modern digital system is complicated. Distributed infrastructure, third-party integrations, changing needs of users, and above all, continuous deployments tend to produce operational risk of the worst kind as a result of seemingly trivial oversights. Anticipating such events could be beneficial for everyone in the long run, promoting digital sustainability.
To anticipate is to actively search for potential failure points across your tech stack, workflows, and dependencies. It means asking:
- Where is our system most vulnerable?
- What kind of stress could break this architecture?
- Are we relying too heavily on any single cloud service, API, or vendor?
- What security threats or compliance risks are emerging in our domain?
This stage is less about reacting to known issues and more about foresight and readiness. The goal is to stay one step ahead of failure, not to scramble when it’s already happening.
Practical Ways to Put Anticipation into Action
Here are some key actions and activities involved in it.
Stage 2: Prepare: Designing Systems That Withstand the Unexpected
Once we identify risks and vulnerabilities in the Anticipate phase, we then build the ability to withstand them. Hence, the Prepare phase.
Preparation means engineering your systems, teams, and processes to work still when things go wrong. It is about ensuring flexibility in your architecture, readiness in your recovery plans, and training your people to respond not with panic but with precision.
This stage turns into action. Teams delivering custom software development services focus on embedding resilience directly into products, infrastructure, and deployment pipelines.
Preparation is both technical and procedural. It involves building systems that can absorb shocks without total failure and defining clear response protocols in the event of incidents.
Key focus areas include:
- Designing fault-tolerant architecture
- Creating redundancy and backup mechanisms
- Strengthening security posture
- Implementing runbooks and playbooks for incident response
- Training teams for rapid decision-making under stress
How Teams Can Put Preparation into Practice
Here is how teams prepare for any unforeseen incident to their system.
1. Resilient Architecture Design
- Use microservices instead of monoliths to reduce blast radius.
- Implement circuit breakers, retries, and rate-limiting to handle failure gracefully.
- Choose a multi-region or multi-cloud deployment to avoid single points of failure.
2. Automated Backups & Disaster Recovery
- Automate backups for all critical data and configurations.
- Define clear RTO (Recovery Time Objective) and RPO (Recovery Point Objective) metrics.
- Regularly test recovery procedures in controlled environments.
3. Load Testing & Chaos Engineering
- Use tools like k6, JMeter, or Gremlin to simulate real-world stress and system failures.
- Validate how systems behave under load, latency, or infrastructure degradation using extensive software testing.
4. CI/CD Pipeline Hardening
- Integrate security checks (SAST/DAST), test coverage analysis, and rollback mechanisms.
- Ensure every deployment follows quality gates that prevent fragile code from reaching production.
5. Runbooks, Playbooks, and Drills
- Document repeatable response plans for known incidents (e.g., database outage, API failure).
- Run incident simulations or fire drills with engineering and DevOps teams.
Stage 3: Absorb: Keeping Systems Stable When Disruption Strikes
Despite the best preparation, disruptions will happen. The real test of resilience lies in how your systems respond in real-time, and that’s what the Absorb stage is all about.
This phase focuses on how well your digital infrastructure, applications, and processes can withstand a shock without breaking down. It’s about system stability during the unexpected—whether it’s a sudden traffic spike, a failed deployment, or a partial outage in a cloud service.
In other words, Absorb is where your earlier anticipation and preparation are put to the test.
When disruption occurs, resilient systems don’t crash—they degrade gracefully. They isolate the issue, limit the damage, and continue delivering core functionality while recovery actions begin.
In technical terms, this means leveraging self-healing systems, redundancy, and intelligent failover mechanisms that can automatically kick in.
How To Build Absorption Capabilities?
Here is how you can create incident absorption capabilities for your system.
1. Fault Isolation and Containment
- Design for service segmentation using microservices or domain-driven design (DDD).
- Implement bulkheads and circuit breakers to prevent cascading failures.
2. Redundant and Distributed Systems
- Use load balancers, failover clusters, and geo-distributed servers.
- Set up hot, warm, or cold standby environments based on system criticality.
3. Autoscaling and Elastic Infrastructure
- Enable cloud-native autoscaling policies to handle load spikes automatically.
- Combine with monitoring systems that trigger dynamic infrastructure adjustments in real-time.
4. Self-Healing Mechanisms
- Use orchestration tools like Kubernetes for automated container restarts or rescheduling.
- Deploy auto-remediation scripts via observability platforms when anomalies are detected.
5. Graceful Degradation
- Design apps to maintain core functions if non-critical services fail (e.g., turning off advanced search if the indexing service is down).
- Communicate transparently with users, using fallback UIs or messaging to maintain trust.
Stage 4: Recover: Getting Back to Full Strength, Fast
Even with the best preparation and built-in absorption mechanisms, some disruptions will impact performance, user experience, or system availability. What matters most in those moments is how quickly and cleanly you can recover.
The Recover stage of the Resilience Lifecycle Framework is all about restoring normal operations with speed, accuracy, and minimal impact, while preserving user trust and preventing long-term damage to your product or reputation.
For software-led businesses, this means combining automated recovery processes, efficient rollback mechanisms, and a straightforward post-incident workflow.
Recovery isn’t just about getting systems back online. It’s about restoring service levels to expected benchmarks, ensuring data consistency, and validating that your environment is safe and stable moving forward.
In technical environments, this often involves infrastructure orchestration, backup restoration, log analysis, security verification, and post-mortem reviews.
How to Recover Data Smarter and Faster?
Here are key ways to ensure faster data recovery for your system in case of an incident.
1. Automated Rollbacks and Failover
- Implement rollback plans in CI/CD pipelines that can revert deployments if issues are detected.
- Use blue-green deployments or canary releases to limit the scope of recovery when rolling back.
2. Disaster Recovery (DR) Playbooks
- Document detailed response plans for different types of outages or breaches.
- Define clear roles and responsibilities for technical and leadership teams.
3. Backup Restoration
- Store frequent, encrypted backups of both infrastructure and critical databases.
- Validate recovery through automated backup testing and data integrity checks.
4. Incident Response Workflow
- Use tools like PagerDuty, Opsgenie, or Statuspage to centralize alerts and streamline communication.
- Maintain runbooks with step-by-step instructions to reduce decision fatigue under pressure.
5. Root Cause Analysis (RCA) & Documentation
- Conduct blameless post-incident reviews to identify what went wrong, why, and how to prevent it in the future.
- Feed learnings into backlog items, architecture updates, or workflow improvements.
Stage 5: Adapt: Learning, Evolving, and Emerging Stronger
Recovery restores your system to its previous state. But Adaptation moves you forward.
The Adapt stage is the final, and arguably the most transformative phase of the Resilience Lifecycle Framework. This is where your organization reflects on what happened, learns from the disruption, and evolves systems, processes, and team culture to become more resilient in the future.
In the enterprise software development approach, adaptation is the secret to continuous improvement. It ensures that every incident becomes a source of innovation, not just a one-time fix.
Adaptation involves systematically analyzing data related to disruptions, identifying patterns, and making iterative adjustments to ensure optimal performance.
It involves:
- Reviewing how systems behaved under stress
- Auditing how teams responded during incidents
- Refining infrastructure and architecture to remove future failure points
- Embedding feedback into the software development lifecycle
How to Operationalize Adaptation?
Here is how you can ensure smoother adaptation of the system according to changing security threat dynamics.
1. Run Postmortems With Purpose
- Conduct blameless retrospectives after every incident.
- Use tools like JIRA, Confluence, or Notion to document learnings and track resolutions.
2. Implement Continuous Improvement Cycles
- Feed insights from incidents directly into your product backlog.
- Update security protocols, infrastructure designs, or QA processes as needed.
3. Monitor Trends and Anomalies Over Time
- Use observability platforms (e.g., New Relic, Datadog) to identify recurring performance or reliability issues.
- Implement data dashboards to track incident frequency, response time, and impact scope.
4. Invest in Team Resilience
- Provide cross-training to reduce knowledge silos.
- Empower teams with time, tools, and autonomy to test and improve systems without fear of failure.
5. Evolve the Architecture Continuously
- Refactor legacy systems to support scalability and resilience (e.g., breaking monoliths into microservices).
- Integrate site reliability engineering (SRE) practices into development and operations.
Wrapping Up
The Resilience Lifecycle Framework gives businesses a practical, structured way to prepare for the unknown, stay online when it matters most, recover faster, and continuously evolve. From anticipating risks to adapting post-disruption, each stage plays a crucial role in how modern systems and teams perform under pressure.
Whether it’s scaling a SaaS platform, modernizing legacy infrastructure, or launching mission-critical apps, resilience is no longer a luxury. It’s your edge.
If you’re ready to build digital products that don’t just survive disruption but thrive through it, we’re the go-to digital transformation partner you need to lead that transformation.