10 Questions to Ask Before You Hire Artificial Intelligence Engineers

Priyanka Wadhwani
Hiring artificial intelligence engineers requires production-focused interview questions, not theory-heavy screening. AI hiring has accelerated, yet many teams still mishire because they assess academic knowledge, generic coding skills, or model vocabulary rather than operational judgment.
If you want engineers who can manage MLOps pipelines, evaluate RAG trade-offs, and own system outcomes in production, you need a sharper interview structure. Most hiring teams still miss that distinction.
This is where the process usually breaks down.
AI/ML hiring grew 88% year over year in 2025, while global demand still outpaced qualified supply. That shortage makes every weak interview decision more expensive. It also raises the cost of false confidence, because an impressive resume can still hide limited production experience.
This guide walks you through 10 questions that help you identify engineers who can operate AI systems at scale, communicate trade-offs clearly, and handle failure responsibly.
Before you add another algorithm round, ask yourself one harder question: Are you screening for production readiness or just technical familiarity?
Why Bad AI Hires Cost More Than Typical Engineering Mis-Hires
Mis-hire artificial intelligence engineers, and you often inherit more than a missed sprint. You add probabilistic debt, monitoring gaps, and delayed failure signals that may not surface until a stakeholder sees output quality fall weeks later.
The financial cost is already high. The average AI engineer salary reached $206,000 in 2025, roughly $50,000 higher than the prior year. The operational cost is usually worse because production ML systems degrade quietly when drift monitoring, evaluation discipline, or rollback controls are weak.
Classify the Role Before You Interview Artificial Intelligence Engineers
Define the role first, because?AI engineer? It is not one job. Analysis of more than 10,000 AI and ML job postings shows that 98.6% of open roles require engineering and operationalization skills rather than pure research depth.
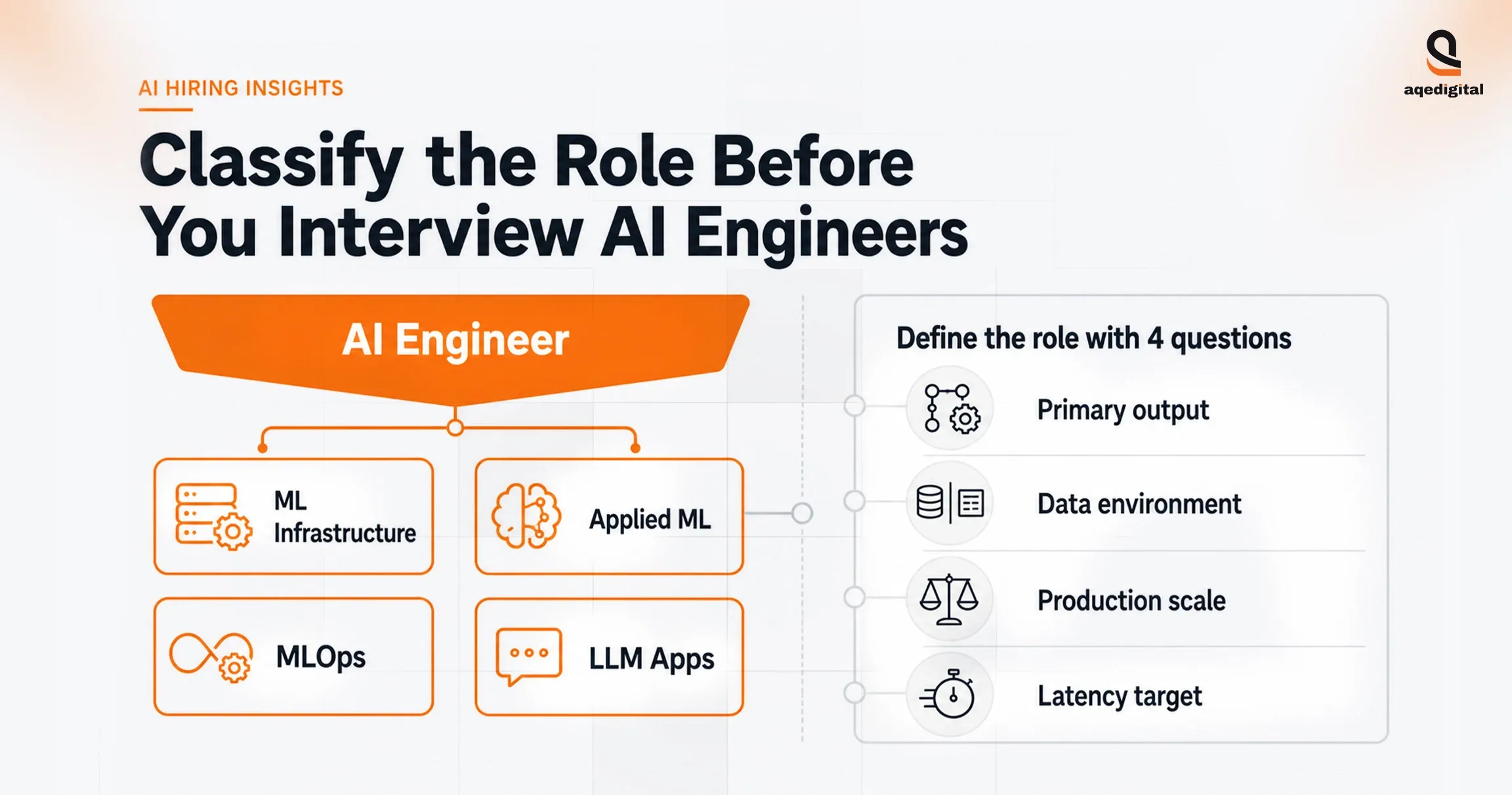 Separate the archetype before you write the assessment. Most companies actually need one of four profiles:
Separate the archetype before you write the assessment. Most companies actually need one of four profiles:
- ML infrastructure engineers
- Applied ML engineers
- MLOps engineers
- LLM application engineers.
Each one solves a different production problem, so each one deserves a different emphasis in the interview.
Answer four internal questions before you publish the job description:
- Define the primary output as a training pipeline, serving infrastructure, deployed model, or LLM application.
- Map the data environment: structured data, unstructured text, or multimodal inputs.
- Set the production scale: experimental, mid-scale API serving, or high-volume inference.
- Clarify the latency requirement: batch inference or sub-200 millisecond service-level performance.
Narrow the archetype with those answers. Then, weigh the interview questions accordingly. Role confusion is not a sourcing problem. It is usually a definition problem inside the hiring team.

10 Questions That Reveal Production-Ready AI Engineers
Use the 10 questions below to test judgment, not trivia. Strong candidates answer with tools, thresholds, trade-offs, and failure stories. Weak candidates stay abstract, stay hypothetical, or rely on textbook language.
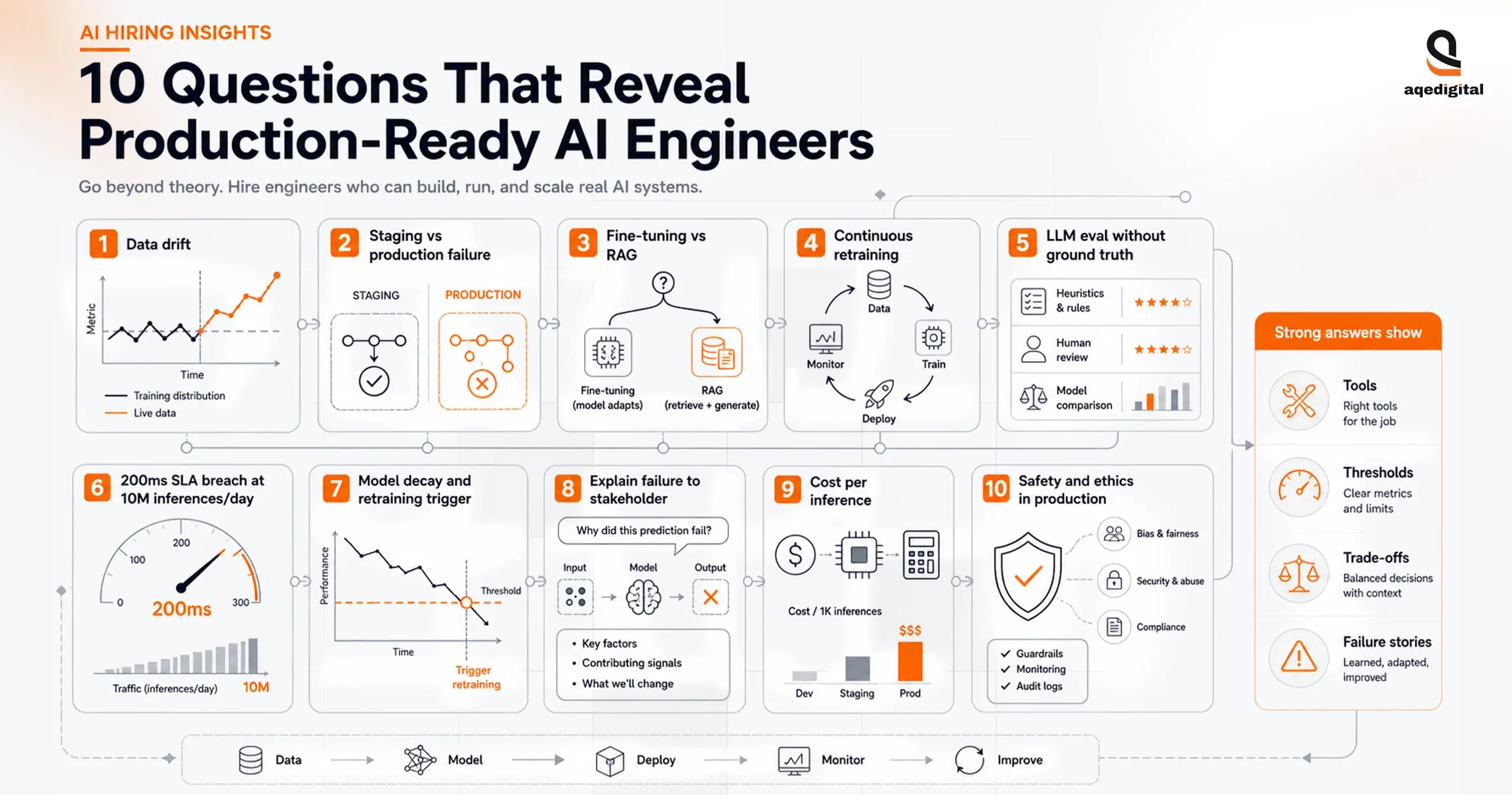
Question 1: How do you detect and handle data drift in a production ML system?
Ask this first to test whether the candidate has operated a live model after launch. A strong answer names a real detection method, such as the Population Stability Index for tabular models or embedding drift monitoring for language systems, then explains alert thresholds, review cadence, and response actions.
Watch for conceptual answers without implementation details. Candidates who cannot name a tool, threshold, or incident workflow usually know the idea but have not owned it in production.
Question 2: Walk me through a model that performed well in staging but failed in production.
Push for a real incident, because this question exposes whether the candidate has debugged a deployed system under pressure. Useful answers usually cover training-serving skew, feature transformation mismatches, pipeline defects, data quality drift, or latency constraints that changed inference behavior.
Treat hypothetical storytelling as a red flag. Production engineers usually remember where the system broke, how they isolated the fault, and what they changed afterward.
Question 3: How do you choose between fine-tuning a foundation model and building a RAG pipeline?
Use this prompt to test architectural judgment. Strong candidates explain that fine-tuning is well-suited to behavior adaptation or task specialization when labeled data exist. In contrast, the RAG fits dynamic knowledge grounding when you cannot afford stale weights or repeated retraining.
Look for trade-off thinking, not tool loyalty. Good candidates discuss latency, maintenance overhead, evaluation complexity, hallucination risk, and the business cost of outdated knowledge.
Question 4: How would you architect an MLOps pipeline for continuous retraining?
Ask for the full system, not a diagram-level summary. Senior answers usually cover upstream data validation, schema checks, drift-based or schedule-based retraining, evaluation gates, shadow deployment, champion-challenger comparison, and rollback controls before broad release.
Push on messy realities, too. Clean pipelines are easier to describe than inconsistent upstream data, but real production environments usually fail at the boundaries.
Question 5: How do you evaluate LLM quality in production when ground truth is unavailable?
Test intellectual honesty here. Strong candidates acknowledge that LLM evaluation is hard, then combine methods such as LLM-as-judge scoring, human review samples, curated prompt regression suites, and supporting signals like latency, refusal behavior, and cost per token.
Candidates who offer one neat metric usually oversimplify the problem. Mature engineers talk about evaluation debt and explain how quality slips without a review system.
Question 6: A service handling 10 million inferences per day has breached a 200 millisecond SLA. How do you diagnose it?
Drive the discussion toward bottleneck isolation. Strong answers separate model inference time, preprocessing overhead, network latency, queueing, cold starts, and infrastructure provisioning. They also name real tools such as OpenTelemetry for distributed tracing or NVIDIA Nsight for GPU profiling.
Listen for sequencing. Good engineers narrow the search space first, rather than guessing at model optimization before they understand where the latency actually lies.
Question 7: How do you manage model decay, and what signal triggers retraining?
Use this question to test long-term ownership. Strong answers explain the monitoring setup, threshold design, retraining authority, business-impact tolerances, and whether human approval lies between retraining and promotion.
Expect nuance. Sensible candidates admit that trigger levels vary by use case, risk exposure, and data volatility rather than pretending one threshold fits every system.
Question 8: Describe a time you explained an AI system failure or limitation to a non-technical stakeholder.
Assess communication, because AI failures are often probabilistic and hard to explain. Strong engineers translate calibration, drift, or retrieval failure into operational consequences that a product or business leader can act on.
Avoid candidates who hide behind technical language. If they cannot explain the issue clearly in an interview, they will struggle when the stakes are higher in production.
Question 9: How do you calculate cost per inference and optimize it under a fixed compute budget?
Test business judgment, not just system design. Strong answers break down token or compute costs, explain batching, caching, quantization, and model-size trade-offs, and define the acceptable accuracy loss at which cost reduction becomes worthwhile.
Push for specific decision rules. Engineers who have owned budget-sensitive systems usually speak in thresholds, trade-offs, and service constraints.
Question 10: What framework do you use to assess whether an AI system is operating safely and ethically in production?
Treat this as an operational governance question. Strong answers cover bias checks across groups, adversarial testing, jailbreak resistance, output filtering, escalation paths, audit logging, and review ownership when anomalous behavior appears.
Do not settle for philosophy. Production teams need safety practices that can be executed, measured, reviewed, and improved.

Build a Behavioral Rubric Before You Hire at Scale
Translate each question into a scoring rubric, because prompts alone do not create consistency. Score responses across three levels: junior signal, where the candidate explains the concept correctly; mid-level signal, where the candidate has implemented it with supervision; and senior signal, where the candidate has owned the system end-to-end and can describe failed decisions as clearly as successful ones.
Define thresholds before interviews begin. For example, a senior production AI engineer may need at least a score of 2 across all 10 questions and a score of 3 on several of them. Set the standard early because post hoc calibration often reintroduces pedigree bias and subjective preferences.
Watch for three red flags that scoring alone can miss. Flag candidates who stay architectural but never name a tool or metric. Flag candidates who outsource judgment to?the team? without explaining their own position. Flag candidates who cannot describe a meaningful failure story. Real production engineers almost always have one.
Use an Interview Structure Designed for AI Work
Replace generic algorithm rounds with an AI-native interview structure when the role is responsible for real production outcomes. A high-signal 90-minute process can work well when you split the time across four segments: problem framing, walkthrough of a shipped feature, live debugging, and cost or architecture judgment.
| Recommended AI Engineer Interview Structure |
|
|
|
|
Build the live exercise around realistic failures. Use a RAG pipeline that retrieves irrelevant chunks, an embedding model that produces unstable similarity scores, or an MLOps pipeline that deploys a degraded model without raising an alert. Observe how the candidate frames the problem, what clarifying questions they ask, and how they sequence the investigation.
Probe stewardship, not just launch competence. Senior artificial intelligence engineers think about model behavior six months after deployment, not only at release time. That operating mindset is often the clearest difference between a researcher and an AI operator.
Conclusion
Hire artificial intelligence engineers with a process built for signal, not volume. The strongest hiring systems classify the role early, test production judgment with the right 10 questions, score answers with a clear rubric, and structure interviews around real operational work.
If your current process still rewards theory over ownership, it will continue to produce expensive uncertainty. Build the interview around how AI systems behave in production, and you will make better hiring decisions with fewer misses.
If you want to audit or rebuild your AI hiring process, connect with our team for an interview rubric review and a production-ready assessment framework.