Enterprise Search Solutions: How AI Is Transforming Information Discovery?

Priyanka Wadhwani
Organizations across business domains are facing an unprecedented rise in fragmented data stored in silos across departments. The greater hassle for every knowledge worker across these organizations is the productivity bottleneck.
In fact, research shows that employees across enterprises spend 20% of their work week just searching for internal information. What does this mean for a 1000-person organization? A whopping $3 million is lost in productivity annually.
AI-powered enterprise search solutions help organizations overcome this productivity bottleneck by leveraging large language models (LLMs), semantic vector embeddings, and Retrieval-Augmented Generation (RAG). It enables AI-powered enterprise search capabilities, ensuring systems understand the true intent behind user queries.
However, most organizations struggle to shift towards an AI enterprise search paradigm due to doubts about whether it’s worth their investment. The reason is the lack of evaluation metrics and knowledge of the productivity gains that AI enterprise search solutions offer.
This guide covers what enterprise search solutions are, why legacy systems fail at scale, exactly how AI search works, which industries are seeing the fastest ROI, and how to evaluate the six leading platforms in 2025.
What Are Enterprise Search Solutions?
Enterprise search applications are software platforms that index and retrieve data from all over an organization's network of interconnected data sources, such as emails, intranets, SharePoint, Slack, CRM, ERP, and cloud storage, in response to natural language questions asked by employees and customers.
The difference from the traditional web search engine lies in the architecture of the solution. An enterprise search platform searches the data in a restricted environment, recognizes document-level access permissions, searches through the repository of disconnected systems, and produces ranked results that are contextual to the user asking.
The state-of-the-art technology in this space understands users' intent, learns from user behavior, and delivers synthesized responses from various data sources instead of just links.
Why Traditional Enterprise Search is Failing at Scale
Most companies don't have a search problem. They have an infrastructure problem that search makes visible, and the four failure modes you identified are exactly where that infrastructure bleeds out.

Here's what changes when you replace legacy retrieval with modern AI search and RAG architecture.
Keyword Search Doesn't Know What You Mean
Legacy search matches characters. It does not match the intent. A query for "parental leave policy" returns nothing if the HR document is titled "paid time off for new parents" because no character string overlaps, and the system was never designed to care about meaning.
Modern AI search resolves this through vector embeddings: concepts mapped mathematically so that semantic distance, not string proximity, determines relevance.
The query and the document don't need to share a single word. They need to share a meaning. That shift alone eliminates a category of failed searches that most organizations have learned to work around rather than fix.
Data Silos Don't Collapse on Their Own
The average mid-sized company runs across 100-plus disconnected SaaS applications. Information lives in Jira, Slack, Salesforce, Confluence, and Google Drive simultaneously and in no single one of them completely.
Modern AI search deploys a unified retrieval layer: pre-built connectors pulling from all of those systems simultaneously. The employee stops needing to know where the answer lives. They ask one question.
The system synthesizes one answer from whatever exists across the stack. That's not a workflow improvement. That's an architectural shift in how organizational knowledge operates.
Stale Permissions Are a Liability, Not Just an Inconvenience
Legacy systems cache permission snapshots. By the time a query runs, those snapshots may be weeks out of date. Modern AI search enforces permissions at query time, not at index time, which means access rights are verified the moment the question is submitted.
Whether the result surfaces to a CFO or a junior analyst depends on role-specific entitlement logic applied live. Personalization is a byproduct of enforcing security correctly.
Outdated Indexes Are a Different Problem Than People Think
Continuous indexing processes new content in near real-time. That's the operational floor, not the ceiling. The more consequential shift is the industry's move toward the Model Context
Protocol, which lets the AI bypass the index entirely and query live source systems directly, though MCP adoption varies sharply by vendor maturity and data architecture.
For volatile data like support tickets, pipeline status, and financial records, this isn't a performance improvement. It's a reliability requirement. Pre-built indexes cannot serve decision-makers operating on fast-moving data.
Why Copilot and Gemini Fail Without This Foundation?
General-purpose AI tools don't have access to your internal data. That's not a product flaw. That's a design constraint you can't prompt your way out of. RAG fixes it by tethering the LLM to a unified, permission-aware search index, which means the model reads your actual documents before it generates an answer, not after.
Citations become traceable to the source document. The model stops generating from memory and starts retrieving from your actual systems, which means hallucinations surface as retrieval gaps rather than confident wrong answers. For enterprise deployments, that distinction is not a feature differentiator. It's the baseline.

Traditional vs. AI-Powered Enterprise Search:
| Traditional Search vs. AI-Powered Enterprise Search | ||
| Capability | Traditional Search | AI-Powered Enterprise Search |
| Query Understanding | Keyword matching | Natural language processing and semantic intent |
| Data Source Coverage | Single or limited repositories | Unified index across all connected systems |
| Result Relevance | Keyword frequency ranking | Contextual, behavioral, role-aware ranking |
| Answer Format | List of document links | Direct answers, summaries, and cited sources |
| Personalization | None | Role, history, and permission-aware |
| Index Freshness | Scheduled batch updates | Near-real-time continuous indexing |
| Knowledge Synthesis | Users read and cross-reference manually | Synthesizes information across multiple documents |
| Compliance Handling | Manual permission filtering | Automated access control enforcement |
How AI-Powered Enterprise Search Works?
AI-enabled enterprise search does not merely enhance the keyword search algorithm. The entire technology stack undergoes replacement here. Here is the four-step process that makes AI search different from other search algorithms.
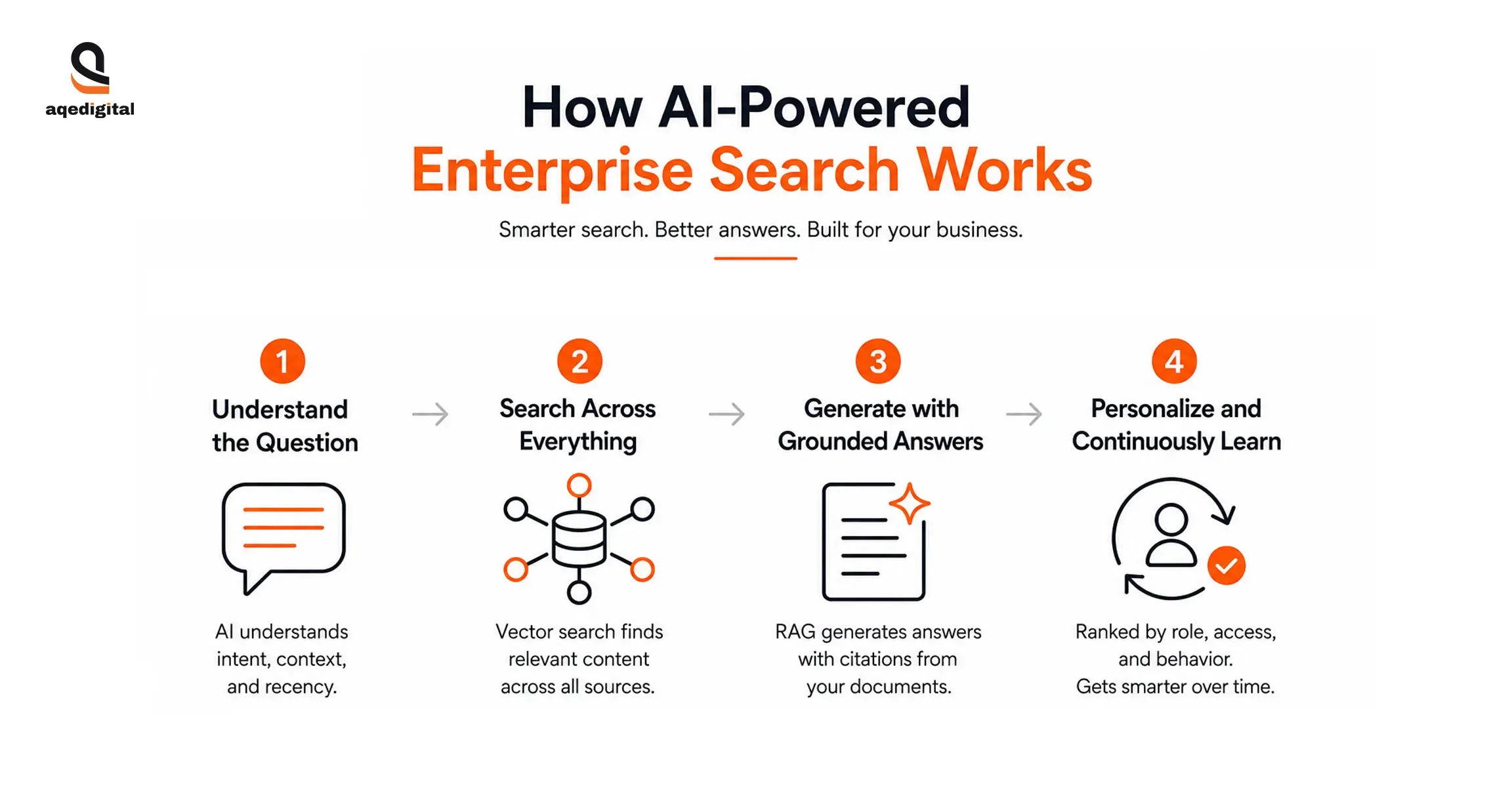
1. Natural Language Processing and Query Understanding
The input is received as a semantic question posed by the employee. When asking for 'the current escalation procedure for a Tier 2 client complaint', the system understands that the employee asks about a process and recognizes 'current' as a signal for recent documents. The search scope becomes procedure documents only.
2. Vector Indexing Across All Connected Sources
Enterprise search powered by AI encodes all documents as vector embeddings, mathematical vectors that contain semantic information about each document. Any file, whatever its type or source system, gets encoded to the high-dimensional space where similar concepts get clustered. The search engine finds relevant content regardless of the different wording of the query and the document itself.
3. Retrieval-Augmented Generation (RAG)
The most relevant chunks of documents get retrieved from the vector index and fed into a generative model, which generates the final answer. This answer is not a hallucination generated from the training data. This answer contains the citation of the source and is generated directly from your company's documents.
4. Personalized Ranking and Continuous Learning
Based on the role, team, permissions, and search history, the personalized ranking layer sorts out the results after the retrieval. The sales engineer gets the templates before the wiki pages.
The compliance officer gets the regulatory documents on top of his search results. And all of this is continuously learned.
Enterprise AI Search Use Cases by Industry
The ROI case for enterprise search solutions isn't theoretical anymore. It's in production across industries where information retrieval was quietly consuming operational capacity that no one had formally assigned a cost to. Here is where AI-powered enterprise search is delivering measurable outcomes today.
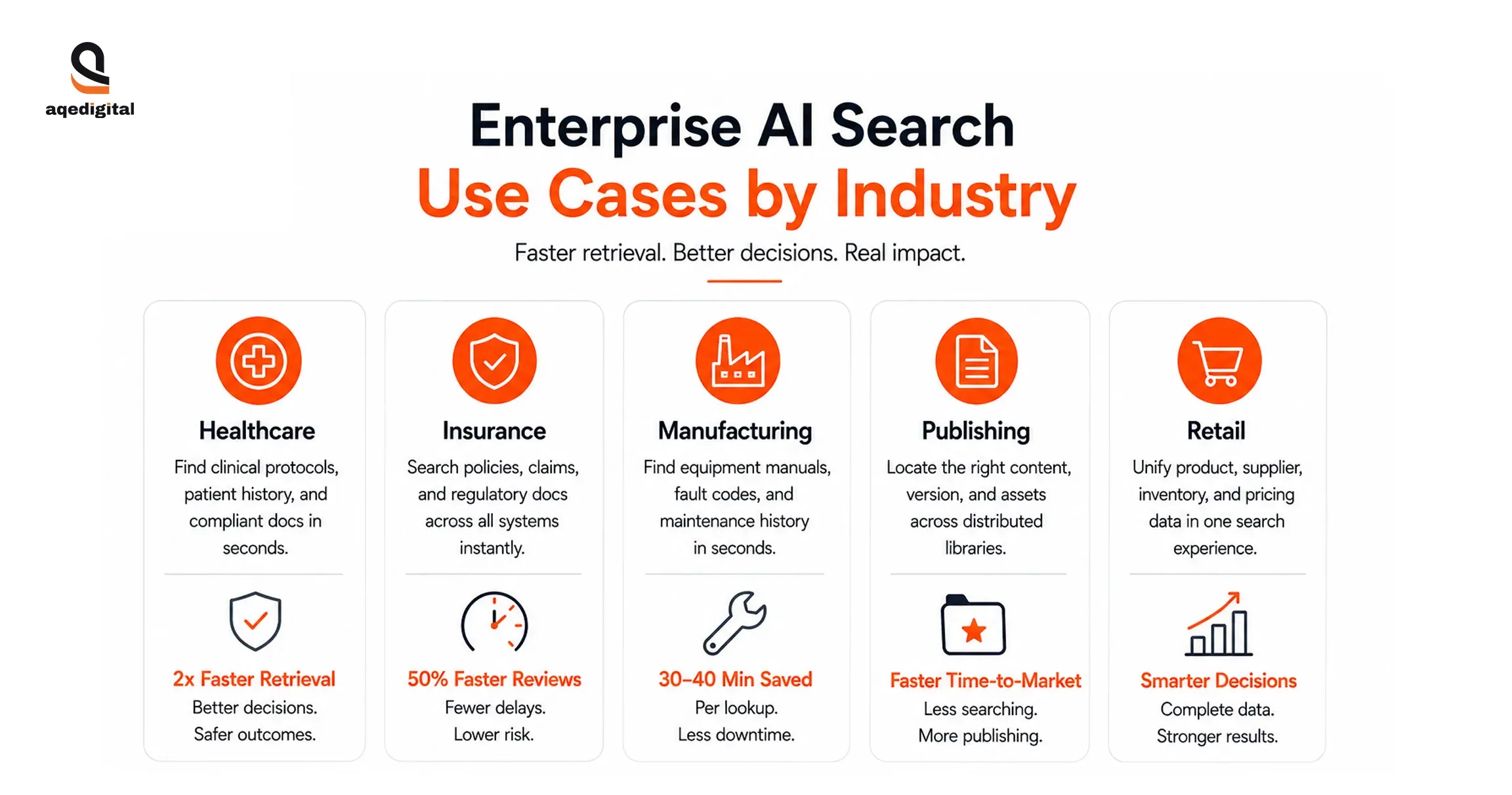
1. Healthcare: Retrieval Speed Is a Patient Safety Variable
Clinical teams don't have a knowledge problem. They have a retrieval problem. Nurses and physicians navigate multiple EMR systems to locate care protocols, cross-reference patient history, and pull HIPAA-compliant documentation, often routing requests through administrative staff who weren't hired to function as search intermediaries. The information exists. Getting to it in under two minutes is the unsolved part.
AI enterprise search changes that timeline. AQe Digital's Healthcare AI solutions are built to surface current clinical protocols in seconds, search patient histories across multiple EMR entries simultaneously, and return compliant documentation without opening a ticket. The productivity return is real. The more consequential gain is accuracy: clinical teams operating on current, verified information rather than the nearest available version.
Whether that accuracy holds depends entirely on how well the underlying data architecture is governed, which is the variable most healthcare AI deployments underestimate at the outset.
2. Insurance: Claims and Compliance Run on Retrieval Speed
Insurance carriers don't lose on pricing alone. They lose on operational velocity. Underwriting documentation, claims histories, coverage terms, and regulatory filings live across systems that weren't designed to communicate with each other.
The result is review cycles that stretch across days when the underlying data already exists inside the organization, but it just can't be found quickly enough to matter.
AI-driven enterprise search closes that gap. AQe Digital's Insurance software development services enable claims teams and compliance officers to search across policy records, regulatory filings, and case precedents from a single query interface.
Fraud investigation teams surface related claim histories that previously required manual cross-referencing across three separate systems. The speed gain is the visible outcome. The less visible one is the reduction in compliance exposure that comes from investigators working on complete information rather than partial retrieval.
3. Manufacturing: Maintenance Downtime Is a Search Problem Wearing a Technical Hat
A heavy manufacturing operation running 10,000-plus pieces of equipment carries documentation across equipment specs, serial numbers, maintenance histories, fault codes, and supplier bulletins.
Finding the right manual for a specific compressor model under a legacy search environment takes a field technician 20 to 40 minutes. Multiply that across daily maintenance cycles at a mid-size facility, and the lost labor hours become significant before a single repair is completed.
A fast enterprise search engine reduces that lookup to seconds by cross-referencing all relevant documentation in a single query. AQe Digital's AI and Data Solutions for Manufacturing are built for exactly this retrieval architecture: structured and unstructured data unified under a single query layer that field teams can operate under time pressure.
The productivity return on that use case alone typically justifies the deployment cost within the first quarter of operation.
4. Publishing: Editorial Workflows Stall at the Content Discovery Layer
Publishing organizations manage large, fragmented content libraries: manuscripts, digital assets, version histories, rights documentation, tagging schemas, and multi-format conversion files.
The editorial workflow slows not because the process is broken but because finding the right version of the right asset, across the right system, at the right stage of production, takes longer than it should.
AI search for enterprise publishing addresses the retrieval layer directly. AQe Digital's Process and Workflow Automation services enable editorial teams to locate specific content versions, tagging records, and production status across distributed repositories in a single query.
Organizations with large content libraries report a measurable reduction in asset discovery time per production cycle. The downstream effect is faster time-to-market, with fewer editorial hours consumed by search that should be seconds, not minutes.
5. Retail: Product Data Fragmentation Costs More Than Stockouts
Retail enterprise teams don't suffer from a lack of product data. They suffer from the same product data living in four different systems with four different formats, none of which talk to each other at query time.
Merchandising decisions, supplier documentation, inventory records, and pricing history sit across separate platforms. Getting a coherent answer requires touching all of them manually, which means decisions get made on incomplete information or don't get made fast enough to matter.
AI-powered enterprise search resolves this by unifying retrieval across the full data stack. AQe Digital's Online Retail Solutions enable merchandising and operations teams to surface product records, supplier terms, and inventory data from a single query interface.
The teams that deploy enterprise search tools alongside unified retail data architecture stop making decisions from partial information. That shift is worth more than the productivity gain. It changes the quality of what gets decided.

Leading Enterprise Search Platforms: 2025 Comparison
Choosing among enterprise search solutions requires matching platform architecture to your existing technology ecosystem, organizational scale, and primary use case. Here are the six leading platforms in 2025.
| Leading Enterprise Search Platforms in 2026 – Comparison Overview | ||||
| Platform | Best For | AI Capability | Deployment | Pricing Model |
| Microsoft Azure AI Search | Microsoft 365 / SharePoint organizations | Semantic ranking, Copilot integration, vector search | Cloud (Azure) | Consumption-based |
| Glean | Google Workspace and Slack-heavy organizations | Unified work search, LLM answer synthesis | Cloud (SaaS) | Per-seat subscription |
| Coveo | E-commerce, support portals, enterprise personalization | Relevance AI, behavioral ML, A/B ranking | Cloud / Hybrid | Usage + seat-based |
| Sinequa | R&D, pharma, regulated manufacturing | Domain-specific NLP, compliance-grade audit | On-premise / Hybrid | Enterprise license |
| Elastic Enterprise Search | Developer-centric, custom search applications | Hybrid BM25 + vector search, open-source | Cloud / Self-hosted | Subscription + managed |
| Amazon Kendra | AWS-native, cloud-first organizations | NLP-based FAQ retrieval, connector ingestion | Cloud (AWS) | Per-query / indexed |
Platform selection is a consequential decision. The wrong fit drives integration cost up and adoption rates down.
The Real Cost of Waiting on Enterprise Search
Most organizations don't decide against deploying enterprise search solutions. They defer the decision and spend the deferral period absorbing costs they haven't learned to measure yet.
That gap matters for a specific reason: the productivity loss from information friction doesn't appear on a budget line. It appears in extended review cycles, decisions made on incomplete data, and onboarding timelines that stretch weeks longer than they should because new hires can't find institutional knowledge without asking three people first. Those costs exist whether or not the organization has named them.
The implementation gap is where most enterprise search deployments either succeed or stall. Skipping the data landscape mapping phase because a vendor promises quick deployment is the single most common reason search projects fail to produce measurable ROI within the first year.
AQe Digital's AI and Data Solutions practice approaches enterprise search implementation the same way it approaches every data engineering engagement: discovery before configuration, governance before deployment, measurable baselines before any outcome claim.
That sequence is slower than a demo-to-production sprint. It also produces deployments that are still running correctly at the 18-month mark rather than being quietly deprioritized after the initial rollout enthusiasm fades.
Talk to AQe Digital's AI search specialists about what a production-grade implementation looks like for your data environment.