Enterprise Data Warehouse: Architecture, Solutions, and Best Practices for Higher ROI

Cheta Pandya
Global organizations generate more transactional data in a single quarter than they did in an entire decade just fifteen years ago. Yet the persistent problem isn't data volume, it's the inability to trust it.
Research from Gartner, estimate that poor data quality costs enterprises an average of $12.9 million per year, and most of that damage originates from siloed systems that report different numbers for the same metric. An enterprise data warehouse changes that equation by establishing a single, governed source of analytical truth across every business function.
This guide covers what enterprise data warehousing actually involves,
- Architecture layers that separate reliable implementations from expensive failures
- Deployment models worth comparing honestly
- Software platforms leading the market
- Best practices for the period during which you get your ROI.
So, let’s get started.
What Is Data Warehousing and Why Enterprises Can't Afford to Get It Wrong
Data warehousing is the discipline of consolidating structured, semi-structured, and historical data from disparate operational systems, ERP platforms, CRMs, financial applications, and marketing tools into a single, analytically optimized repository.
The warehouse doesn't replace your transactional databases; it reads from them, transforms the data through a standardized ETL (extract, transform, load) process, and makes it available for reporting, predictive modeling, and business intelligence at scale.
What separates an enterprise data warehouse (EDW) from a departmental reporting database is scope, governance, and architectural rigor. A departmental database serves one team's queries.
An EDW serves the entire organization simultaneously with,
- Finance tracking margins
- Analyzing campaign attribution
- Operations monitoring supply chain throughput
That concurrency requirement is where most underpowered implementations collapse.
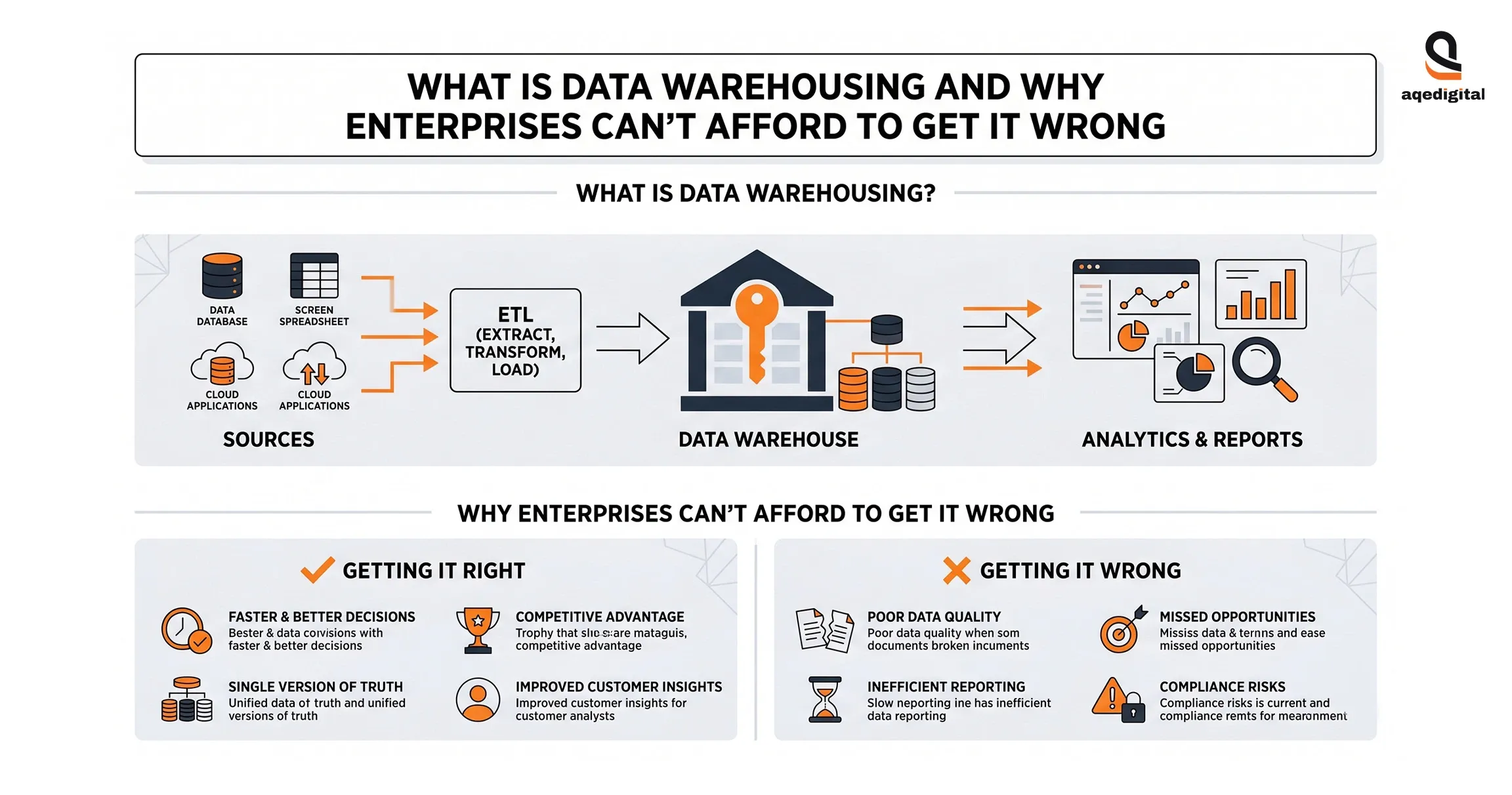
The financial stakes are not abstract. When a sales team's revenue figure doesn't reconcile with finance's for the same period, the company has a data credibility problem that eventually surfaces in board presentations, investor reporting, and regulatory filings.
A well-designed EDW eliminates that reconciliation overhead entirely by providing a single authoritative version of each metric to every stakeholder. That alone justifies the investment for most mid- to large-sized enterprises.
Why Data Warehousing Services Have Evolved Beyond Simple Reporting
Modern data warehousing services extend far beyond the batch-reporting use case that defined the field through the 2010s. Today's implementations support real-time streaming ingestion from IoT sensors and web applications, and feed machine learning pipelines with cleaned and labeled training data.
AWS, Microsoft, and Google have each invested substantially in making these extended capabilities native to their cloud data warehouse platforms rather than requiring separate infrastructure.
The Data Silo Problem That Makes Enterprise Data Warehouse Investment Justified
An enterprise with twelve source systems and no centralized warehouse typically operates with twelve different definitions of 'customer,' 'revenue,' and 'active user.' Merging those definitions post-hoc for a board report requires manual reconciliation that a competent analyst can spend days on each month.
According to IDC research, data professionals spend up to 80% of their time managing and preparing data rather than analyzing it, a figure that reflects the operational cost of fragmented data infrastructure, not an analytics team problem.
Enterprise Data Warehouse Architecture: The Three-Tier Model That Underpins Every Reliable Implementation
Modern enterprise data warehouse architecture follows a three-tier design that separates data collection, storage, and consumption into distinct, independently maintainable layers. This separation matters because the failure mode of monolithic warehouse designs, where a change to ETL logic breaks reporting dashboards, is eliminated when tiers are properly decoupled.
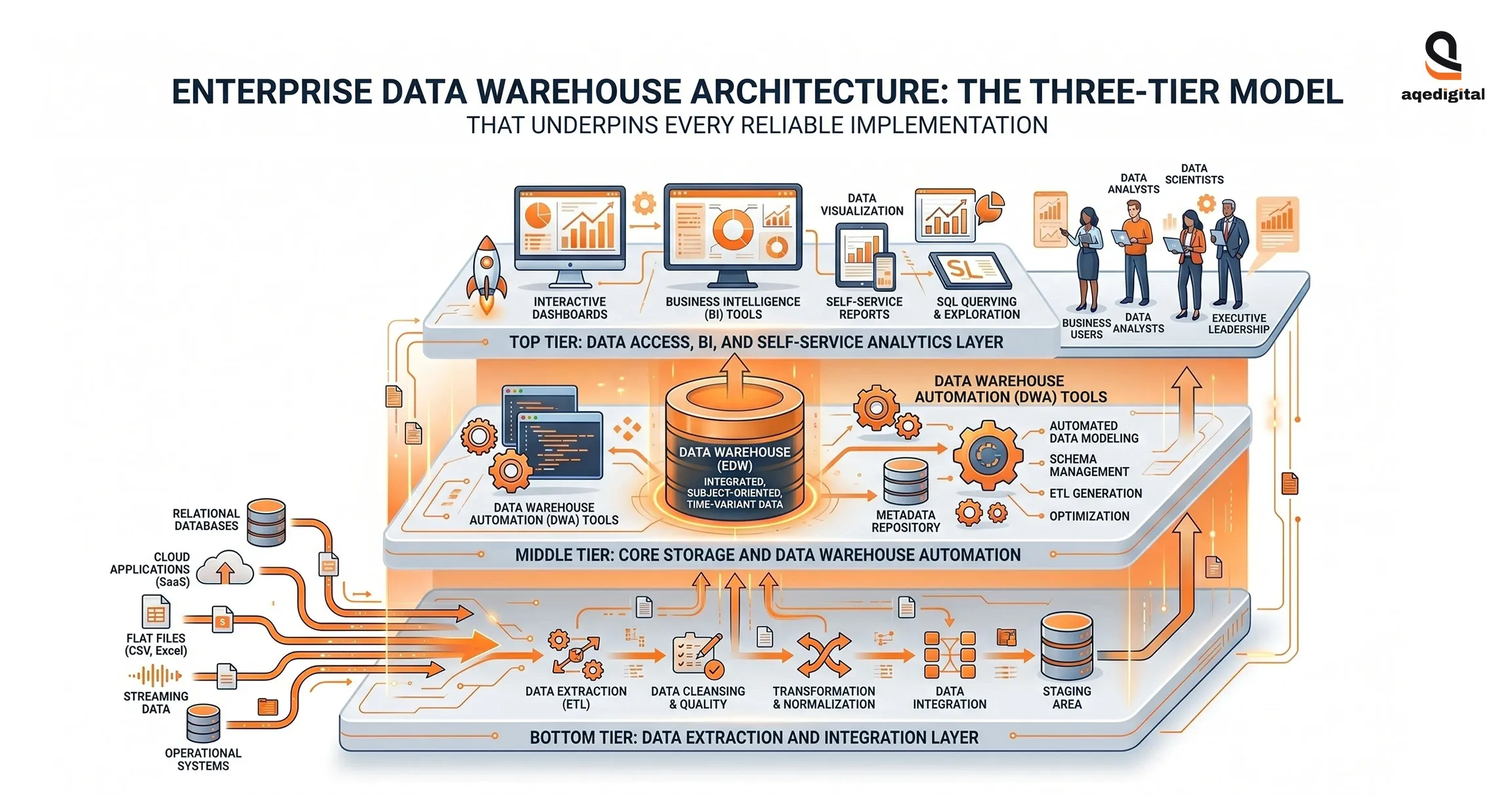
Bottom Tier: Data Extraction and Integration Layer
The bottom tier connects to every source system and manages the ETL process: extracting data from operational databases, cleansing duplicates, correcting format inconsistencies, applying business rules, and staging the transformed data for loading.
The quality of transformation logic at this layer determines the accuracy of everything built on top. Organizations that rush through bottom-tier design, treating ETL as a connectivity exercise rather than a data quality investment, inevitably spend their first year of warehouse operation fixing logic that should have been correct at launch.
Middle Tier: Core Storage and Data Warehouse Automation
The middle tier is the warehouse itself, the governed repository that stores integrated data in structures optimized for analytical queries rather than transactional writes.
Two dominant schema patterns exist:
- A star schema organizes data into a central fact table surrounded by dimension tables and performs well for most standard reporting workloads.
- Data Vault, which provides full audit lineage and handles frequently changing source system schemas, is a better choice for regulated industries or organizations with volatile data sources.
Data warehouse automation tooling has fundamentally changed build timelines at this tier. Platforms like WhereScape compress the manual development of ETL code, schema design, and deployment scripts from months to weeks by generating those artifacts programmatically.
Organizations using automation typically see EDW delivery timelines compress by 60–70% compared to hand-coded approaches, a material difference when business units are waiting on analytical capabilities to make operational decisions.
Top Tier: Data Access, BI, and Self-Service Analytics Layer
The top tier is what most stakeholders interact with daily: the BI tools, dashboards, self-service query interfaces, and reporting layers that sit above the warehouse.
Platforms like Tableau, Power BI, Looker, and ThoughtSpot connect directly to the warehouse and provide pre-built visualizations and natural language query capabilities so non-technical users can extract insight without writing SQL.
The critical design principle here is access governance, which defines which users can query which data sets directly and which require masked or aggregated views to meet regulatory or privacy requirements.

Data Warehouse Solutions: Cloud, On-Premises, and Hybrid Deployment Models Compared
No deployment model is universally superior. The decision depends on the regulatory environment, existing infrastructure investments, internal technical capability, and the total cost of ownership calculation across a realistic five-year horizon, not just the headline per-TB storage price.
Cloud Data Warehouse Solutions: Scalability Without Infrastructure Overhead
Cloud data warehouse solutions, led by Snowflake, Amazon Redshift, Google BigQuery, and Microsoft Azure Synapse Analytics, have become the default choice for organizations without legacy infrastructure dependencies or strict data residency requirements.
The global cloud data warehouse market is projected to grow from $36 billion in 2026 to $155 billion by 2034, at a CAGR of 17.5%, per market research data cited by DataCamp's 2026 platform comparison analysis, a trajectory that reflects enterprise adoption, not hype.
Snowflake's architecture separates compute and storage into independently scalable layers, making it well-suited for organizations with variable query concurrency. Amazon Redshift holds over 34% of cloud data warehouse revenue, according to DataCamp's competitive analysis, and benefits from deep integration with the AWS ecosystem.
BigQuery's serverless model eliminates cluster management and handles unpredictable workloads without manual provisioning. The right platform depends on your cloud ecosystem, existing skill set, and whether your query patterns favor concurrency (Snowflake) or bursty, unpredictable workloads (BigQuery).
Read more: Data Warehouse Vs Data Lake Vs Data Lakehouse: Select the Right Approach For Your Business
On-Premise Data Warehouse: When Data Sovereignty Demands It
On-premise data warehouse deployment remains relevant in two specific contexts: organizations operating under strict data sovereignty regulations that prohibit cloud residency (e.g., certain government agencies, financial institutions in specific jurisdictions), and enterprises with legacy systems whose integration complexity makes cloud migration a multi-year project with high execution risk.
The operational model is clear: you own the hardware, manage the patching cycles, and control the network access perimeter. The tradeoff is capital expenditure, specialist staffing requirements, and limited ability to scale compute elastically in response to analytical workload spikes.
Hybrid Architecture: Managing Compliance Alongside Cloud Efficiency
Hybrid deployments split workloads between on-premise and cloud infrastructure based on data classification. Sensitive regulated data, patient records, and financial transactions subject to audit remain on-premise behind a controlled perimeter. Less sensitive workloads, development environments, and ML training pipelines run in the cloud, where elastic scaling keeps costs proportional to actual usage.
The architectural complexity of maintaining synchronization between environments is the primary cost driver in hybrid implementations; teams that underestimate this coordination overhead tend to see hybrid deployments drift into technical debt within 18 to 24 months.

Enterprise Data Warehouse Best Practices That Separate Successful Implementations from Costly Failures
Most enterprise data warehouse projects that run over budget share a common root cause: the team treated the warehouse as a technology project rather than a data strategy initiative. The technical work is the easier half. The harder work is establishing governance structures, defining business-aligned data ownership, and building stakeholder alignment before a single ETL job runs.
Governance, Lineage, and Quality from Day One
Governance cannot be retrofitted. Organizations that build a warehouse first and define governance policies later spend years correcting the consequence: undocumented transformation logic, inconsistent business rule application across departments, and data lineage gaps that surface as compliance liabilities during audit.
The effective practice is to define data ownership and who is accountable for the accuracy and business definition of each data domain during architecture design, not after deployment.
Data lineage tooling, which tracks every transformation step from source system to dashboard, has shifted from an optional enhancement to a near-mandatory component in regulated industries.
For enterprises operating under SOX compliance, GDPR data access requirements, or HIPAA audit trail obligations, the inability to demonstrate exactly how a reported figure was derived creates audit exposure.
Compressing Build Cycles Without Sacrificing Quality
Manual EDW development for a 200-table warehouse can generate upwards of 400 ETL packages, each requiring individual coding, testing, and documentation. That scale creates two problems simultaneously: long initial build timelines and inconsistent implementation quality across developers.
Automation platforms address both by generating transformation logic from metadata rather than requiring developers to hand-code each process individually.
The operational benefit compounds over time: automated documentation stays in sync with the actual implementation, whereas manually written documentation typically diverges during the first major schema change cycle.
Measuring EDW ROI: The Metrics That Justify Investment
A real-world enterprise data warehouse example from a SaaS company illustrates how measurable ROI emerges. After centralizing product usage data in a cloud EDW, the company identified that users who failed to engage a core feature within their first 30 days were 50% more likely to churn.
That single insight, extracted from a unified behavioral dataset that would have been impossible to query across siloed tables, drove an automated onboarding campaign that reduced first-year churn by a material margin. In that case, the warehouse ROI wasn't efficiency savings; it was a revenue retention number.
For enterprises benchmarking their expected returns, the most reliable metrics are: reduction in report reconciliation hours per month, time-to-insight for ad hoc analytical requests, and the financial value of decisions made with accurate versus estimated data.
Organizations evaluating their QA and software testing service investments alongside warehouse implementation should factor in the testing overhead of ETL logic; poorly tested transformation pipelines are among the most common sources of data quality failures that undermine warehouse credibility in the first year of operation.
Enterprise Data Warehouse Software: Evaluating Platforms Beyond the Feature Matrix
Feature matrices lie. Snowflake, BigQuery, Redshift, and Azure Synapse look comparable at the headline level. Real differentiators don't appear in analyst tables.
Vendor Lock-in Risk
Underweighted in most evals. Redshift has a genuine integration win for AWS-native organizations, and real switching costs if cloud strategy shifts. Snowflake multi-cloud = more flexibility, less depth in AWS-native tooling. BigQuery serverless = no infra management, but billing is unpredictable without query-governance from day one.
Alignment With SaaS Product Architecture
If you are building or modernizing SaaS alongside EDW, the choice of warehouse platform is a product decision, not just an infra decision. The platform determines which analytical APIs product teams access, how multi-tenancy data isolation is enforced at the warehouse layer, and how reporting workloads are isolated from transactional loads.
Operational Maturity Tooling
Most underweighted criterion: monitoring, alerting, lineage visualization, and cost governance dashboards. A platform that excels technically but ships no operational observability = warehouse team builds it from scratch. The total cost of ownership model must explicitly capture staffing costs.
Query Performance and Concurrency Handling
Benchmark against your actual workload pattern, not vendor benchmarks. Snowflake virtual warehouses isolate workloads cleanly. BigQuery slot-based concurrency needs capacity planning. Redshift concurrency scaling adds cost. Azure Synapse workload management needs manual tuning. Concurrency behavior under peak load reveals more than single-query speed.
Cost Governance and Billing Predictability
Serverless models (BigQuery, Synapse Serverless) shift cost risk to query behavior. Compute-based models (Snowflake, Redshift) shift risk to provisioning decisions. Neither is safer without governance. Enforce query cost limits, auto-suspend idle warehouses, and tag workloads by team before users hit production.
Enterprise Data Warehouse Strategy in 2026: The Decisions That Compound Over Time
An enterprise data warehouse is not a project with a delivery date. It is infrastructure that organizations grow into over the years, adding data sources, expanding analytical use cases, and building increasingly sophisticated ML and AI applications on top of a foundation that either supports that growth cleanly or creates friction at every extension point.
The architecture decisions made in the first twelve months, schema design, tier separation, governance policy, and automation tooling determine which of those trajectories an organization follows.
That compounding dynamic is why the investment in getting the first implementation right exceeds the marginal cost of any individual feature. Organizations that establish clean, well-governed data warehouse foundations in 2026 will be operating AI-augmented analytical applications on that same infrastructure in 2028. Those who rush to deployment without proper architectural discipline will have to rebuild.
Enterprise data warehousing in 2026 rewards organizations that treat it as a strategic data capability, not a technology installation. The platforms are mature, the automation tooling is proven, and the economics of cloud deployment are favorable. What separates the high-ROI implementations is the discipline applied before the first line of transformation code is written.