Data Bias in AI/ML: Practical Solutions For An Ethical Challenge

Cheta Pandya
Data is one of the most powerful elements for business in the current digital landscape. Using data responsibly, reliably, and accurately is crucial for companies and data experts. The field of data science and AI/ML is ever-evolving and it remains a critical challenge for data experts to process data maintaining ethics, accuracy, and fairness. Businesses are heavily relying on data-driven insights to make informed decisions and it makes the risk of biased algorithms to be addressed more profoundly. From manufacturing to marketing to supplying, biased algorithms can have far-reaching and detrimental effects on businesses, affecting their decision-making based on data.

Organizations are making heavy investments in AI, however, data bias remains a challenge that can be overcome if taken care of. Data bias in models can harm the outcomes eventually impacting decision making and business operations. It is crucial to address the challenges of data ethics and bias given the widespread usage and integration of ML, AI, and other data platforms.
Data bias can manifest in various stages of analytics- it could be from how a data question is hypothesized and the way datasets get sampled and organized. Data bias can surface at any stage of the data processing journey ranging from defining and capturing the dataset to running analytics, AI, or ML systems. Solving data bias must be prioritized for accurate results and desired outcomes. If left unchecked, bias can undermine the insights and decisions that organizations seek from their data-driven processes.
What is Data Bias?
Human brains and senses have a natural trait to comprehend the surroundings and experiences instinctively seeking patterns in data. Like the human brain, AI/ML models rely on neural networks that comprehend the data they are trained with to analyze and deliver the outcomes. In simple words, data bias is a phenomenon occurring within AI/ML algorithms providing inaccurate or prejudiced results due to mistaken assumptions in the modeling process. This kind of data bias leads to incorrect, unfair, and discriminatory outcomes out of the data.
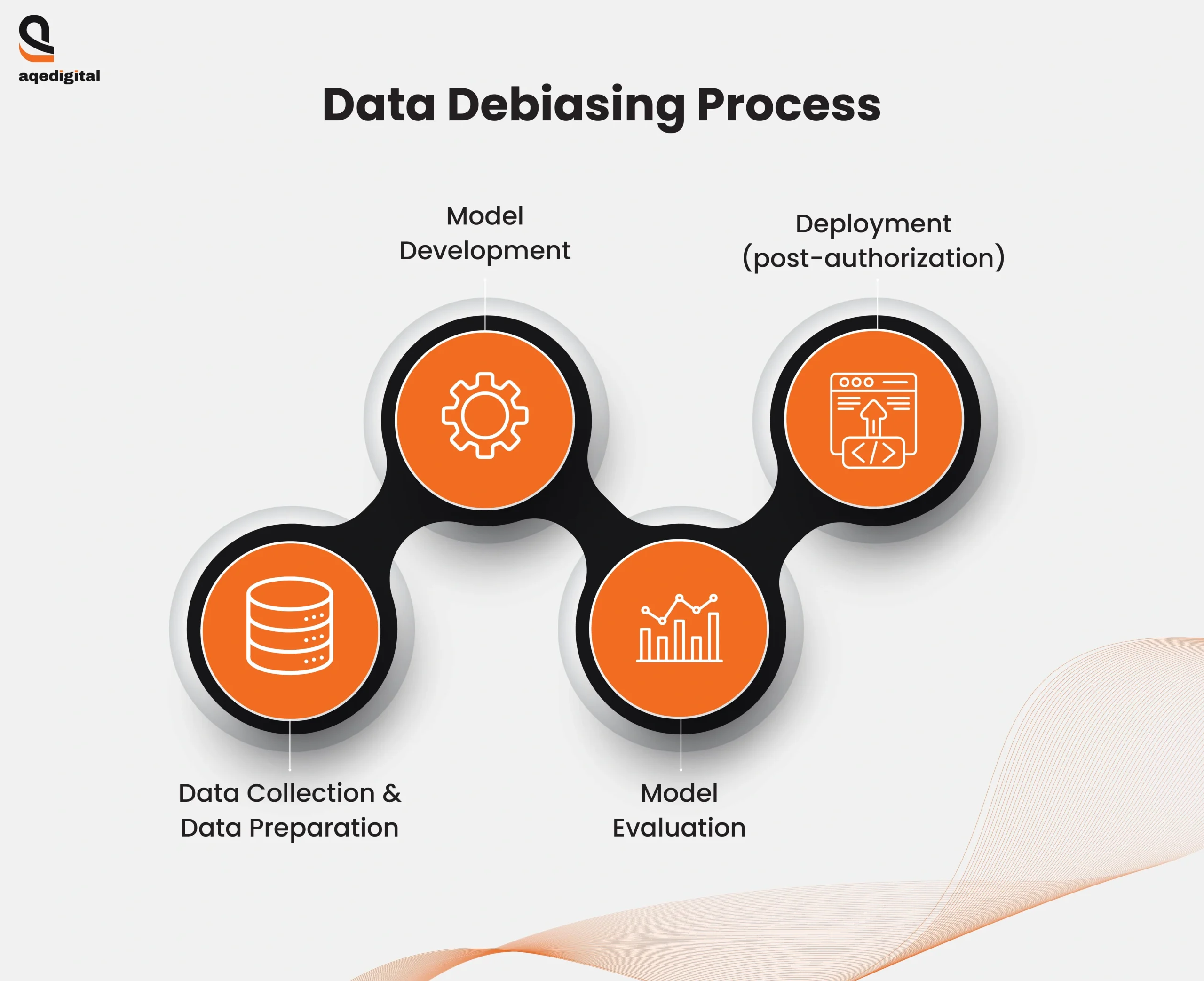
Different Types Of Data Biases and Their Solutions
Data bias can addressed by treating data ethically and practicing fair approaches to maintain the privacy and accuracy of the data. Having a good data set and treating it with an unbiased perspective is crucial for accurate outcomes. The AI/ML models can have different biases such as race, gender, replication, preference, and others. There are many ways to solve data bias challenges like model auditing and implementation of bias detection tools to make the data more accurate and reliable.
Here are common data biases that could happen during data processes:
1) Confirmation Bias
It happens when preference is given to information that aligns with the existing beliefs or opinions, often without realizing it. This bias leads to emphasizing data that supports the personal viewpoint, influencing the way data is gathered and analyzed unconsciously reinforcing the hypothesis.
How confirmation bias can be avoided:
To mitigate confirmation bias, start by clearly defining your research question, hypothesis, and the objectives of your data analysis before collecting any data. Actively challenge the data you’re working with by seeking evidence that contradicts your assumptions. Once the analysis is complete, carefully compare the results with your initial hypothesis to ensure an objective assessment.
2) Historical Bias
Historical bias arises when past cultural norms, prejudices, or societal beliefs shape the data that was collected, and it can continue to influence present-day data. This bias often reflects ingrained human biases, discrimination, or outdated beliefs, and it can hinder the development of accurate machine learning models by feeding them biased information.
How historical bias can be avoided:
Regularly audit your data sources to identify and correct for historical biases ensuring that underrepresented groups are considered and included in data frameworks. To prevent inaccuracy in future analysis recognize and address the bias in both historical and contemporary datasets.
3) Selection Bias
Selection bias occurs when the data sample does not properly represent the target population, leading to skewed insights. This error often arises from poor study design, such as selecting a non-random or too-small sample.
There are three common types of selection bias:
- Sampling bias: When the data is not gathered randomly.
- Convergence bias: When data is collected in a way that doesn’t accurately represent the population.
- Participation bias: When participants self-select into groups, which distorts the results.
How selection bias can be avoided:
To minimize selection bias, address historical biases and seek to diversify your data sources. Use larger, more randomized samples to better reflect the population. Additionally, make adjustments to your research design to correct for potential selection bias in both current and future studies.
4) Survivorship Bias
Survivorship bias is a cognitive error where we focus on the data points that made it through a selection process while overlooking those that didn’t. This often leads to faulty conclusions due to incomplete visibility of all data.
There are two key ways survivorship bias distorts analysis:
- Inferring causality: Assuming that a specific factor caused an outcome when the relationship between them might not exist.
- Inferring a norm: Believing that the data that survived represents the norm, without considering the data that was lost.
How survivorship bias can be avoided:
Evaluate the data sources that are included and ensure that none of the relevant data gets excluded or omitted.
5) Availability Bias
Relying too heavily on information that is recalled easily mostly or that is readily available leads to distorted conclusions leading to availability bias.
How availability bias can be avoided:
Actively seek out opposing viewpoints and data that challenge the current beliefs. Such data may be harder to locate, but it helps ensure that the analysis isn’t disproportionately influenced by the most easily accessible information.
Benefits Of Unbiased Data To Businesses
- Enhanced Decision-Making – More accurate, objective decisions that drive business success.
- Increased Customer Satisfaction – Fair and personalized experiences to diverse customer segments can be delivered.
- Better Market Insights – Deep insights into consumer behavior and market trends, enabling smarter strategies.
- Improved Operational Efficiency – Data-driven improvements are based on real, unbiased insights, optimizing resource allocation.
- Stronger Brand Reputation – Helps build trust and credibility, enhancing the brand image of the organization.
- Risk Mitigation – Reduces the risk of making faulty business decisions that could lead to financial loss or compliance issues.
- Higher Revenue Growth – Helps identify real growth opportunities, leading to better sales and revenue outcomes.
- Optimized Marketing Strategies – Businesses can create more effective, targeted marketing campaigns by eliminating data bias.
- Increased Innovation – Bias-free data fosters fresh ideas and solutions, pushing the business toward innovation and new product development.
- Compliance and Ethical Leadership – Ensuring data integrity helps businesses stay compliant with regulations and lead ethically in the market.
Practical Example Of Debiasing Data
1) Data Bias in Automated Recruiting Processes
Data bias in the automated recruiting process can significantly affect the selection of candidates. For instance, there is a chance for the algorithm to select candidates from certain demographic groups, races, genders, or educational backgrounds that have been consistently hired in the past if it screens resumes referring to the historical hiring data. Such bias can lead to the exclusion of qualified candidates from underrepresented groups, creating an unfair recruitment process.
Solutions:
- Feeding Diverse Data: Represent a broad spectrum of demographics, experiences, and skills by training the algorithm with diverse datasets.
- Implementing Bias Detection Tools: Use bias detection software to flag potential biases in the recruiting algorithm’s decision-making process.
- Weightage: Applying weightage gives different importance or priority to specific data types that are either underrepresented or overrepresented in the dataset. It helps balance the impact of various data inputs for more accurate predictions.
- Regular Audits: Perform frequent audits to ensure the system’s fairness and adjust models when bias is detected.
- Diverse Testing Groups: Test the system’s performance on a variety of demographic groups to ensure equitable outcomes across all candidates.
- Bias Reduction in Model Development: Ensure that the development process of algorithms follows strict guidelines to reduce bias from the start.
- Ethical Guidelines: Making the decision-making process fair and accurate by the implementation of ethical AI frameworks.
2) Data Bias in Predictive Maintenance for Manufacturing
In predictive maintenance, data bias can skew equipment failure predictions, as the system might be trained on incomplete or biased data that represents specific machines or operational conditions. This can lead to misallocated maintenance resources, over-servicing certain equipment while neglecting others, and ultimately reducing the efficiency of maintenance schedules.
Solutions:
- Feeding Diverse Operational Data: Train predictive models using diverse data from various machines, shifts, and operating conditions to ensure accurate predictions.
- Implementing Bias Detection Tools: Utilize bias detection software to identify and address biases in the maintenance prediction models.
- Regular Audits: Conduct regular audits of the predictive maintenance system to ensure data inputs and model outputs remain balanced and unbiased.
- Cross-Machine Validation: Test the system across multiple types of equipment to ensure consistent predictions without favoring certain machines.
- Data Sampling Checks: Regularly check the sampling methods to ensure data is representative of all operational conditions, avoiding over-reliance on historical data from specific machines or shifts.
- Dynamic Data Updates: Continuously update the data pool with recent operational data to prevent outdated or biased insights from affecting predictions.
- Ethical Maintenance Frameworks: Develop ethical AI guidelines to ensure the maintenance system prioritizes fairness and efficiency in resource allocation.
- Inclusivity in Data Collection: Ensure all operational data, including underrepresented shifts or machines, is included in the model to provide an accurate maintenance outlook.
Conclusion
With more and more data production, it continues to shape various aspects of businesses in terms of decision-making, planning, operation efficiency, workflows, productivity, and many more. Businesses and data experts must prioritize minimizing bias to ensure fairness, equity, and accuracy within data used to train AI/ML models. By adopting an ethical approach encompassing transparent algorithmic design and constant monitoring, implementing bias detection tools and other strategies to curb data bias organizations can mitigate the associated risk.
At AQe Digital, our data experts leave no stone unturned to make the most out of data to deliver the accurate and best outcomes by treating data with the right approach maintaining ethics, principles, and business objectives. Contact us to harness the true capabilities of your data and experience the best data solutions leveraging our 25+ years of expertise.