
In 2025, companies are leveraging AI assistants, real-time pricing, and personalized experiences through data pipelines. Successful teams treat these pipelines as products, focusing on Service Level Objectives (SLOs) and clear data use agreements. Those who don’t adapt risk delays and failures in data-dependent features.
Organizations often face challenges like inefficient handoffs, unexpected data structure changes, and outdated dashboards, which can lead to soaring cloud costs. Gartner predicts cloud costs for organizations across domains to reach $723.4 billion by the end of 2025. Due to inconsistent data, the leadership struggles with understanding data freshness, accuracy, and expenses.
The issue lies in building flexible and reliable data pipelines that can manage both batch and streaming data while maintaining quality. With complex environments and strict service agreements, it’s crucial to manage data flow and track changes effectively.
This guide details how to create a production-ready Python-based data pipeline, covering data ingestion, schema registries, contract testing, automated validation, and comprehensive monitoring. It provides deeper and clearer insights with diagrams and analytical charts, real-world examples, and a step-by-step approach to streamline workflows for CTOs, project managers, and senior data architects. So without wasting much time, let’s get started.
What is Data Pipeline Architecture?
Data pipeline architecture is the design and structure of systems that enable the automation of information transformation from different sources. It includes an end-to-end flow of data to help you efficiently manage and create value from raw information. Data pipeline architecture is like a blueprint for how data moves, processes, and is used within your system.
The main goal of deploying data pipelines is to convert raw, heterogeneous data into a clean, standardized dataset. Using these datasets, Power BI, dashboards, and machine learning algorithms can help you offer real-time insights into operations. It also enables you to map how multiple data pipelines connect, the necessary tools for the connection, and how orchestration is managed.
Using data pipeline architecture, you can even manage governance and monitoring, ensuring accuracy of operational insights. Knowing what a data pipeline is and building one are two different things. If you are planning on how to create a data pipeline, the first aspect you need to cover is the core principle.
What Are The Core Principles of Modern Data Pipeline Architecture?
Data moves fast in today’s world, where real-time insights have become crucial for every operation. Whether you are managing a fleet of cargo ships to transport shipments across the globe or a retail grocery business, without insights, you are simply in the dark. You don’t have the information to analyze, optimize, and maximize outcomes.
Using these principles, you can design data pipelines that can easily handle large amounts of data and offer real-time insights.
1. Modularity and Loose Coupling
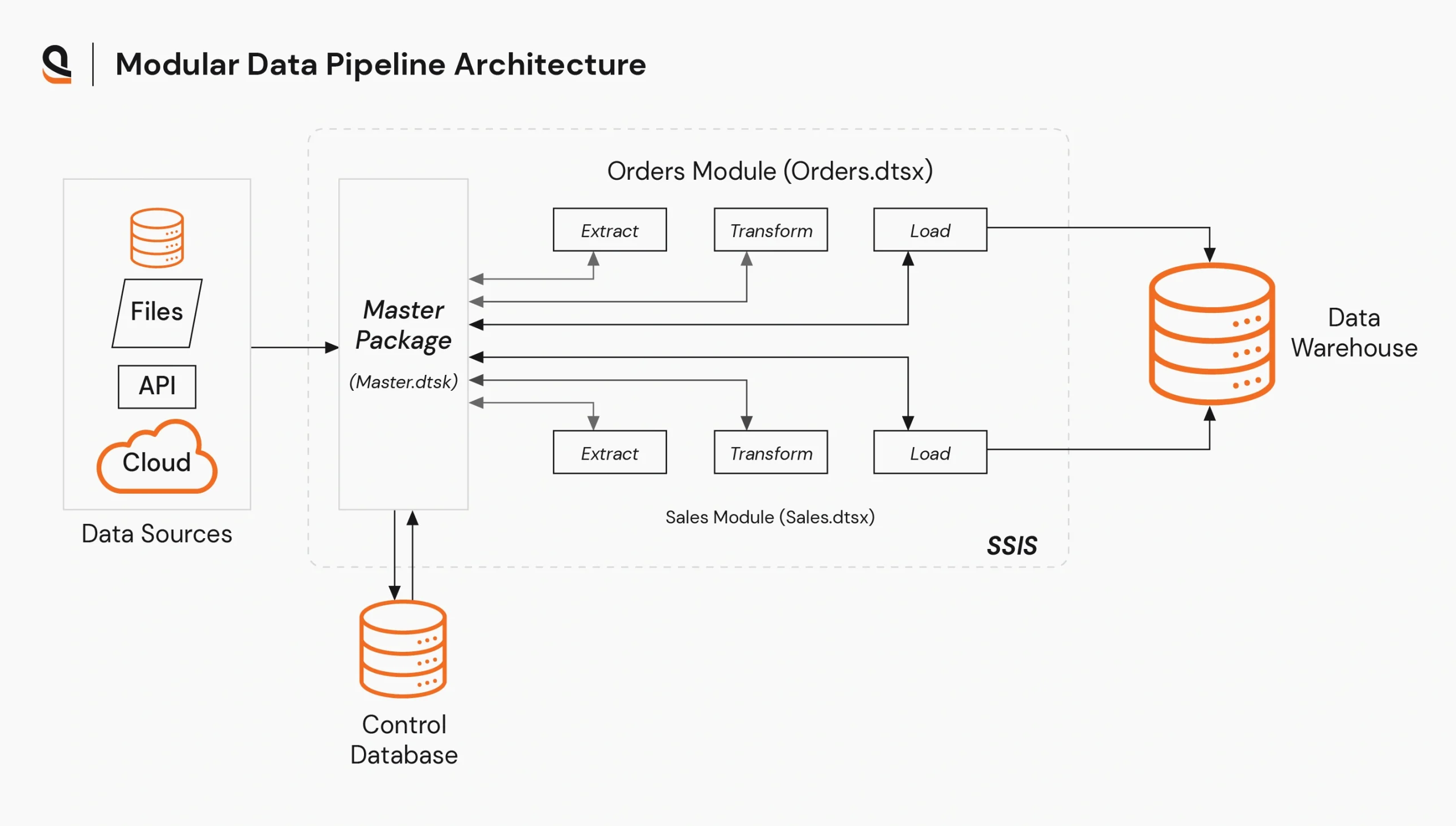
Loose coupling and modularity principles follow a structure of loosely coupled pipelines. Each of the pipelines is independent and communicates through a well-defined interface.
For example, the above data pipeline architecture shows how to build ETL data pipelines in a decoupled manner. Data from multiple sources flows into a “Master Package” and controls separate ETL modules to extract, transform, and load data into a data warehouse for analytics.
2. Scalability and Elasticity
Scalable pipelines adapt to fluctuating workloads without sacrificing performance or cost efficiency. Elastic compute and storage help handle surges, seasonality, and growth while maintaining predictable SLAs.
3. Reliability and Fault Tolerance
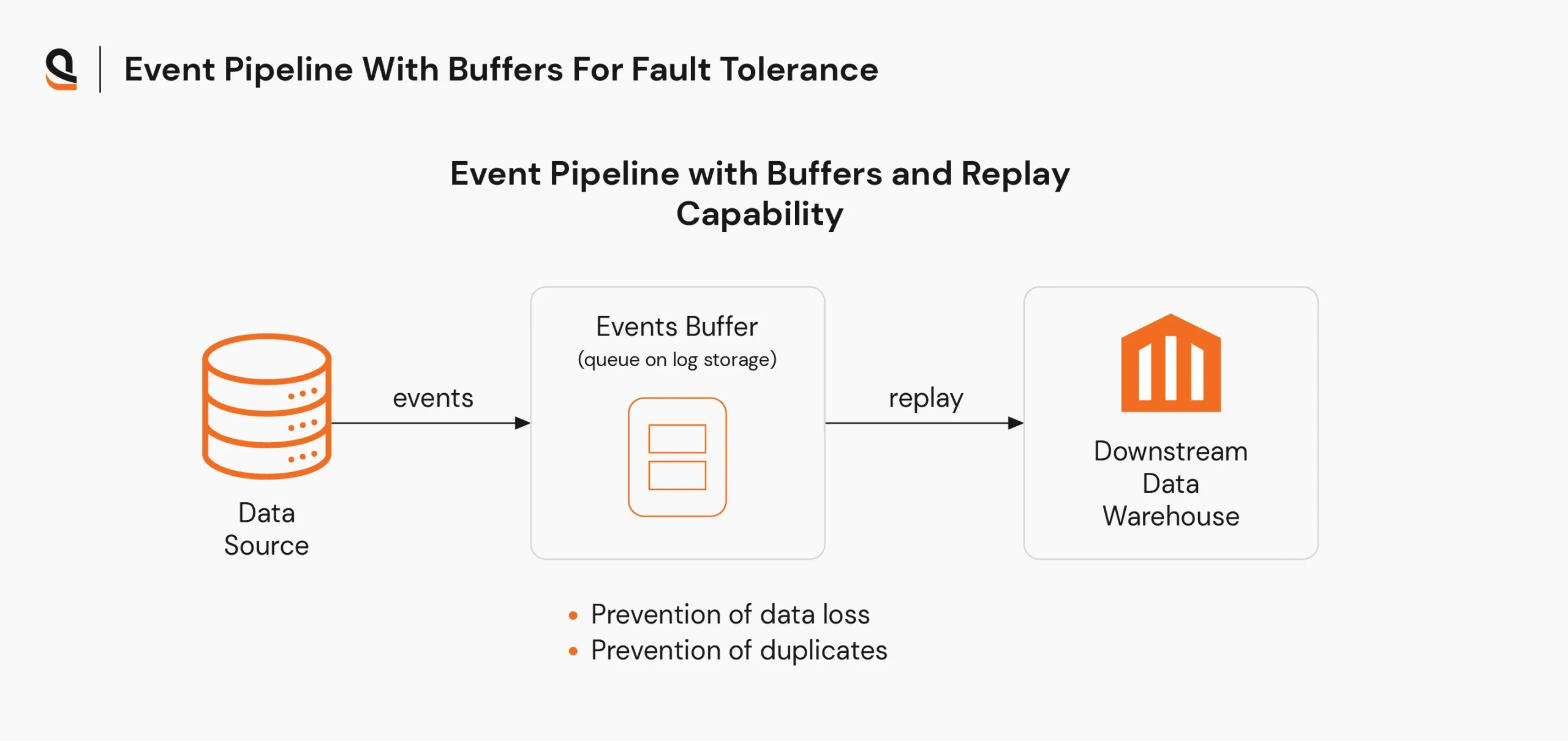
Reliable pipelines assume failures will happen and are designed to recover gracefully. Techniques like retries with backoff, idempotent operations, checkpointing, and dead-letter queues help ensure consistent outcomes.
For example, if a downstream warehouse is temporarily unavailable, the pipeline buffers events and replays them once the service is back, avoiding data loss and duplicate ingestion.
4. Data Quality by Design
Data quality is embedded at every stage: ingestion, transformation, and serving. Validations for freshness, completeness, accuracy, and uniqueness prevent insufficient data from propagating to analytics and ML.
5. Observability and Lineage
End-to-end visibility into pipeline health and data flow is non-negotiable. Metrics, logs, traces, and lineage connect system behavior to data outcomes for faster troubleshooting and impact analysis.
6. Schema Management and Evolution
Sources evolve, and so data pipelines must, too. Schema registries, compatibility rules, and contract testing prevent breaking changes and facilitate safe evolution without downtime.
7. Security and Governance by Default
Security is built in, not bolted on. Least-privilege access, encryption in transit and at rest, secrets management, and policy enforcement protect data assets at every hop.
8. Multi-Modal Processing (Batch + Streaming)
Modern use cases demand both historical depth and low-latency insights. Data pipelines should support batch reprocessing for accuracy and streaming for immediacy, choosing the simplest mode that satisfies the SLA.
Now that you know what a data pipeline is and its core principles, here are some of the key stages and components you must know.
Which Are The Key Stages and Components of Data Pipeline Architecture?
Building data pipelines for your operations requires an understanding of how different components in a pipeline work. Plus, you also need to understand the various stages at which data moves, how it moves, and what the key data pipeline architecture examples are.
Here are the core stages of data pipeline architecture.
1. Data Collection and Ingestion
In this stage, raw data is collected from databases, APIs, files, IoT devices, apps, and logs using batch or streaming ingestion. It is an essential stage for data pipeline architecture mapping.
2. Data Processing/Transformation
In the first stage, data is ingested, and it’s cleansed, normalized, enriched, and transformed. This process also includes filtering, aggregating, joining, and applying business logic to the ingested data.
3. Data Storage/Loading
Data processed in the second stage is then loaded into a designated source such as a data warehouse, data lake, or repository. Such data is then used for further analysis, AI model training, and operational purposes.
All the stages are executed leveraging multiple components of the data pipeline architecture. These components are,
- Data Source – Data originates from them.
- Data Ingestion Mechanisms – Tools and processes that help you extract data from sources.
- Data Processing Engine – Infrastructure and software that processes data and transforms it into valuable insights.
- Data Storage – Final destination for all processed data, where it’s stored for further use.
- Workflow Management and Orchestration – Systems that help you manage and schedule the execution of the data pipeline stages.
- Monitoring and Observability Tools – Mechanisms and tools employed to track data health, performance, and reliability.
- Data Quality and Governance – Processes used to ensure data accuracy, consistency, and compliance with regulations.
Now that you know what a data pipeline architecture is, its components, stages, and core design principles, a key question remains in your mind- “Why Python?”
Why Build Data Pipelines in Python?
Python offers flexibility for you to create robust data pipeline architectures. It also provides an ecosystem with operational reliability, ensuring you can quickly develop prototypes and production-grade workflows.
Libraries like Pandas, NumPy, and SciPy support advanced data transformations for your projects. It enables connections between databases, cloud storage, APIs, and different file formats.
What Are The Key Advantages of Building Pipelines in Python?
- Rich Library Ecosystem: From data ingestion (SQLAlchemy, PySpark) to orchestration (Airflow, Prefect), Python offers end-to-end support.
- Scalability: Pipelines can scale from small prototypes on a laptop to distributed enterprise systems.
- Community Support: A vast developer base ensures continuous improvements, tutorials, and troubleshooting support.
- Cost-Effectiveness: Open-source ecosystem reduces dependency on expensive proprietary tools
What Are The Real-World Use Cases for Data Pipelines in Python?
Here are some of the real-world use cases of data pipelines used in Python.
1. Uber
Uber’s Michelangelo added PyML to let data scientists build in pure Python and deploy the same model across notebooks, batch jobs, and real-time services. At the same time, the platform sustains high-throughput, low-latency predictions, streamlining iteration and productionization at scale.
2. Netflix
Netflix introduced a “ready-to-go” sample data pipeline architecture on Dataflow that includes code, tests, deployment scaffolding, and mock data. It enables teams to bootstrap production-grade batch ETL quickly and standardize pipeline development across the organization.
3. Airbnb
Airbnb safeguards production changes in its data pipeline architecture by combining progressive delivery with automated, contract-driven validation to minimize risk while shipping fast.
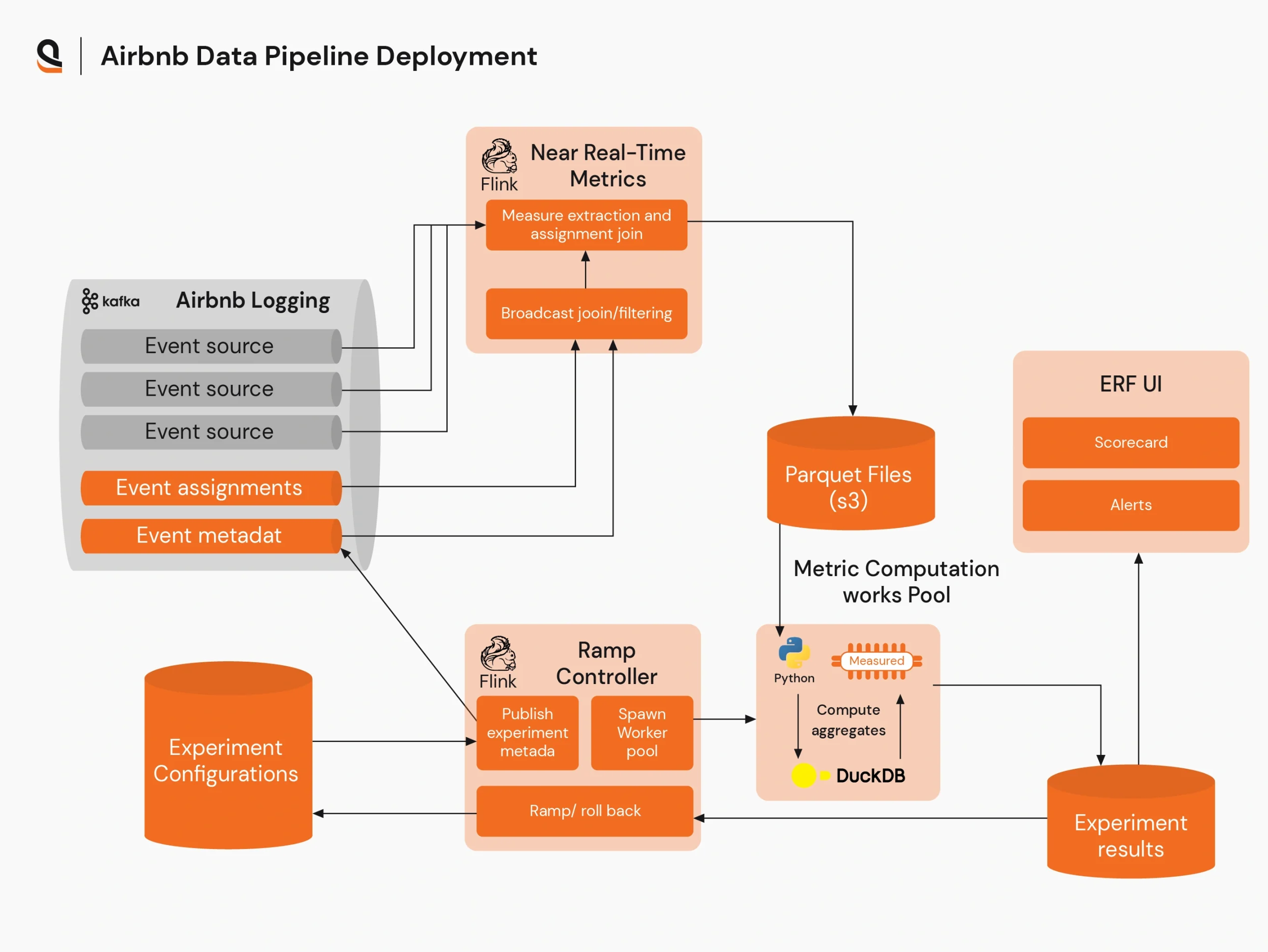
Engineers promote changes from staging to production using techniques like shadowing, dual reads/writes, and canary releases. It compares outputs from old and new paths before shifting traffic, and performs strict schema and version checks to enforce data contracts.
Adding such a mechanism for your business can help reduce standing issues and improve production efficiency. To add such a system, you need data analytics services with expertise in data pipeline deployments. Now that you know real-world use cases, it’s time for implementation. But before you implement data pipeline architecture in Python projects, here are some of the challenges that you need to overcome.
What Are The Common Challenges in Data Pipeline Architecture?
Deploying data pipelines in Python requires managing a large volume of data, handling diverse data sources, maintaining data quality, and addressing security issues. All of this adds to the data pipeline architecture deployment challenges.
1. High Data Volume
Handling large amounts of data, like terabytes or petabytes, can create problems with storage speed, network capacity, and processing power. This often results in failing to meet service levels, long delays in data recovery, and unstable operations, especially if the data is unevenly distributed or poorly organized.
Large data transfers and complex joins can increase memory usage and cause data to overflow onto disk storage. Additionally, having too many small files or files that are too large can slow down reading and writing processes.
Expert Solution:
2. Heterogeneous Data Sources
Pipelines collect data from structured databases, semi-structured files, events, and SaaS APIs. These sources have different formats, speed limits, and reliability. Variations in data types, pagination methods, time zones, and how they handle empty values make it difficult to create reliable connections. This inconsistency leads to challenges in normalization and validation.
Expert Solution:
3. Data Quality and Reliability
Schema drift, poorly formatted records, and hidden data problems can weaken trust among customers. It is challenging to ensure idempotency and avoid duplicates when retrying or restoring data across distributed systems.
Expert Solution:
4. Orchestration and Dependency Management
Complex Directed Acyclic Graphs (DAGs) with conditional branches, retries, and backfills can become complex, especially when their dependencies are not well documented. Scheduling these data pipelines based on time can lead to a misalignment with the availability of upstream data, resulting in races and incomplete runs.
Expert Solution:
Overcoming these challenges requires the application of a structured data pipeline architecture in Python. This is where a Python data pipeline framework comes into play. It helps you structure your deployments.
Which Are The Best Python Data Pipeline Frameworks?
Here are some of the best Python data pipeline frameworks that you can leverage for your projects.
| Framework | Primary Use Case | Programming Model | Scaling & Deployment | Integrations & Ecosystem | Learning Curve |
| Apache Airflow | Workflow orchestration for batch pipelines | DAGs authored in Python | Modular architecture that scales to large, complex workflows | Broad plug‑and‑play operators for AWS/GCP/Azure and more | Moderate (DAG concepts, operators) |
| Prefect | Pythonic workflow orchestration with strong failure handling | Python functions/flows | Modular, scales to complex workflows across environments | Cloud/on‑prem, flexible integrations | Easier than Airflow for many teams |
| Dagster | Pythonic workflow orchestration with strong failure handling | Declarative, data‑asset focus in Python | Cloud‑ready, managed offering and custom infra support | Extensive integrations with major clouds, ETL, and BI | Moderate; asset concepts add structure |
| Luigi | Pythonic workflow orchestration with strong failure handling | Task graph (DAG) in Python | Suited to batch jobs; used at scale in practice | Extensible but smaller ecosystem than Airflow/Prefect | Relatively light if staying simple |
| Apache Beam | Unified batch + streaming pipelines with portable runners | SDK for Python; write once, run on Flink/Spark/Dataflow | Portability across Flink, Dataflow, Spark, avoids lock‑in | Extensible; ML/TFX connectors | Higher (streaming abstractions, runners) |
Now that you know what framework to use, it’s time to apply it in a step-by-step process.
6 Practical Ways to Build and Scale Data Pipelines in Python
Designing a modern data pipeline doesn’t have to be overly complex, but it does need to be smart, efficient, and scalable. With Python at your fingertips and the right data operations strategy, teams can now move faster, troubleshoot easier, and adapt pipelines as the business evolves.
Here’s a hands-on approach to building a strong, production-ready pipeline using Python-based tools and modern architecture principles.
Step 1: Define the Workflow
Start by answering a simple question: What problem is your pipeline solving?
Is it powering a dashboard? Feeding a machine learning model? Refreshing daily reports?
For this, you should define:
- Your data sources (APIs, CSVs, cloud storage, databases)
- The frequency of updates (real-time or batch?)
- The end destination (data lake, warehouse, analytics layer)
- Any transformations or enrichments needed before the data is usable
Having this clarity upfront keeps your pipeline focused and easier to manage as it grows.
Step 2: Choose the Right Ingestion Method
Your data ingestion strategy should match the speed and scale of your data. If you need real-time updates (e.g., transactions, user events), go with:
- Apache Kafka, Apache Pulsar, or Python Kafka clients
- Cloud options like AWS Kinesis or Google Pub/Sub
For batch data (e.g., daily CSV files or database extracts), use:
- Pandas, Dask, or SQLAlchemy
- Extract-load tools such as Airbyte, Luigi, or Bonobo
Choose tools that play well with your tech stack and are easy for your team to troubleshoot.
Step 3: Apply Data Transformation and Validation
Once data lands, it often needs cleaning, restructuring, or enriching. Use Python libraries like:
- Pandas or Polars for complex transformations
- Pydantic or Great Expectations for data validation
- NumPy, SQLAlchemy, or JinjaSQL to power flexible logic
Break down transformations into clear, modular steps. This not only makes your data workflow easier to understand but also helps with automated testing and reuse across multiple pipelines.
Step 4: Orchestrate the Pipeline with Python-Based Tools
This is where the magic happens. Orchestration tools help manage the flow, schedule runs, retry failed steps, and monitor everything under the hood. Top Python-native data pipeline tools include:
- Apache Airflow – Best for complex scheduling and task dependencies
- Prefect – Modern, cloud-first with a great developer experience
- Luigi – Simple, suitable for small DAGs (Directed Acyclic Graphs)
- Dask – Ideal for large, parallel workloads or in-memory processing
These orchestration layers give your data pipeline architecture structure, visibility, and resilience—three things every team will appreciate when something inevitably goes wrong.
Step 5: Automate Monitoring and Alerts
Once your pipeline is live, don’t just “set it and forget it.” You will need to add monitoring to track:
- Runtime performance
- Data freshness
- Failed tasks or unusual patterns
Use tools like Prometheus, Grafana, Prefect Cloud, or custom email/Slack alerts to keep your team in the loop. This ensures your data operations stay proactive, not reactive.
Step 6: Build for Scale and Reusability
As your business grows, your pipeline should grow too—without breaking. The best practices include:
- Keep pipeline components modular and loosely coupled
- Use environment variables and config files for flexibility
- Version control your pipeline code (Git + CI/CD is your friend)
- Document your logic and dependencies well
When pipelines are built this way, they can be reused, adjusted, and scaled without duplicating work or introducing risk.
How AQe Digital Can Help You Build a Scalable Data Pipeline Architecture in Python?
A good data pipeline architecture should be easy to track and scale with your data needs. You can leverage batch processing for quicker insights and add streaming for real-time updates. Using data contracts, automated checks, and tracking the origin of each piece of data can help you streamline data pipelines.
Plus, you need to use clear and organized processes, known as DAGs, which are versioned for control. Measuring metrics like data freshness, problem resolution speed, and costs is also crucial for designing an optimal data pipeline architecture.
However, the best way is to leverage an orchestration system designed to streamline operations and ensure optimal data pipeline architecture across the system. AQe Digital’s data analytics services can help you build a robust and cost-effective data pipeline using Python. Contact us if you want to create scalable data solutions.

FAQs
If you’re just learning how to build a data pipeline, starting with Python makes sense. Beginners often combine Pandas, requests, and basic scheduling.
For orchestration, lightweight data pipeline software like Prefect is an excellent entry point before moving to heavier solutions such as Airflow, which is popular in larger pipeline architecture setups.
When planning data pipeline architecture for real-time dashboards, clarify how partitioning is expected, schema evolution, query granularity, and what exactly constitutes a “user request.”
Understanding downstream data consumption is critical, whether you’re delivering metrics, a big data pipeline, or an AI data pipeline for predictive analytics. Gathering these requirements early helps in creating sustainable data pipeline management processes.
A simple way to get started is by creating an example of data pipeline architecture using Python. For instance, load data from a CSV, transform it with Pandas, and then load it into DuckDB or Postgres.
This small-scale building data pipeline example teaches you core concepts before moving into enterprise-scale data pipelines. You could create a data pipeline diagram to visualize data flow, ensuring clarity in each stage of extraction, transformation, and loading.
When evaluating pipeline architecture, consider questions like:
-> What’s my source format (JSON, Avro, Parquet)?
-> How will I handle schema drift?
-> Is throughput closer to real-time or batch?
-> What retry/fault-tolerant mechanisms do I need?
-> How will I document lineage and metadata?
This checklist applies whether you’re designing big data pipelines, experimenting with data pipeline automation, or just reviewing data pipeline best practices. A good design ensures scalability and reliability as your workloads evolve.
Yes. A stack combining Python pipelines, Postgres, Airflow, and DBT is ubiquitous when building data pipelines for MVP or small-scale production. Pandas is a good starting point, but may hit limits at scale.
Tools like DLT for ingestion and SQLMesh for transformation offer flexibility, especially for teams modernizing their data pipeline software. Airflow’s orchestration and scheduling features make it a standard for many data pipeline architecture examples.
To ensure data accuracy, adopt strategies like unit testing, implementing data contracts, and running automated data quality checks. Fault injection techniques can further expose weaknesses in your data pipelines. These checks are part of broader data pipeline management routines, ensuring that your pipeline architecture can handle errors, maintain SLAs, and provide trustworthy insights regardless of whether you’re working on a big data pipeline or an AI data pipeline.