In a world where data is the new currency, ETL pipelines remain the tried-and-true backbone for turning raw information into actionable insights. But what exactly is an ETL pipeline?
An ETL data pipeline is the systematic process of extracting data from multiple sources like databases, APIs, logs, transforming it through cleansing, aggregation, enrichment, and then loading it into a central destination like a data warehouse or lake. This sequence forms the backbone of enterprise analytics, powering everything from dashboards to machine learning systems.

While the modern data stack often highlights ELT, or even no-ETL patterns, traditional ETL pipelines continue to shine in use cases demanding robust governance, consistency, and cross-system synchronization. Enterprises rely on them for scenarios requiring guaranteed data quality, regulatory compliance, or hybrid cloud/on-prem architectures.
Why ETL Pipelines Still Matter
- Massive market momentum: The global ETL software market was valued between USD 4.5 billion and 6.7 billion in 2023–24, with forecasts pointing to 12–13% annual growth, reaching ~USD 12–20 billion by the early 2030s.
- Enterprise dominance: Large organizations represented 62% of ETL software usage in 2023, underscoring the critical importance of industrial-strength ETL data pipeline solutions.
- Cloud-first adoption: Over 69% of ETL software relies on cloud-friendly architectures—a trend enabled by SaaS ETL platforms—while the global Cloud ETL tool market alone was ~USD 6.8 billion in 2023 and projected to grow at ~10.6% annually.
Despite cloud-native innovations, ETL workflows form the critical connective tissue across organizational data ecosystems. Enterprises still rely on them to move data efficiently, enforce governance, and ensure consistency even in real time, as modern architectures evolve.
So What is the Enterprise Perspective?
- Fault tolerance & governance: Enterprises need pipelines built for idempotency, retries, and lineage tracking, not just data movement.
- Hybrid & compliance-first models: Industries like healthcare and finance continue to deploy on-premise or hybrid ETL pipelines due to legal/regulatory constraints.
- Real-time capabilities: Modern ETL data pipeline platforms—Apache Kafka, NiFi, Flink—enable streaming transformations, with many organizations reporting 30%+ performance boosts, less latency, and stronger SLA adherence.
ETL Pipeline Architecture for Scalability
A scalable ETL pipeline architecture is more than just an assembly of extract-transform-load steps—it’s a structured framework built to handle growing data volumes, complexity, and velocity without compromising performance, quality, or governance. Whether you’re migrating legacy systems to the cloud or building net-new pipelines for a real-time analytics stack, the architectural foundation is critical.
Foundational Layers of a Modern ETL Data Pipeline
To build an enterprise-grade ETL data pipeline, it helps to think of the architecture in five core layers:
a. Data Ingestion Layer (Extract)
- Sources: SQL/NoSQL databases, cloud applications (Salesforce, Shopify), IoT sensors, flat files, APIs
- Mechanisms: Batch extraction (scheduled pulls), streaming ingestion (Kafka, MQTT), change data capture (CDC)
b. Transformation Layer
It enriches, cleanses, aggregates, and reshapes data
May include:
- Filtering irrelevant data
- Data joins and lookups
- Derived KPIs or metrics
- Conversions (e.g., currency, units)
It is performed via:
- In-memory frameworks like Apache Spark
- SQL models with dbt
- Cloud-native tools like Google Dataflow
c. Staging & Buffering Layer
Temporarily stores extracted or transformed data for fault tolerance and performance buffering
Staging is crucial for managing:
- Late-arriving data
- Deduplication
- Replay capabilities in case of failure
d. Loading & Storage Layer (Load)
Pushes processed data into final destinations:
- Cloud data warehouses (BigQuery, Snowflake, Redshift)
- Data lakes (S3, Azure Data Lake)
- Operational databases or analytics tools
- Supports both full refresh and incremental loads
e. Orchestration & Monitoring Layer
Workflow engines (Apache Airflow, Prefect, Dagster) manage task sequencing and dependencies
Real-time observability dashboards track pipeline health, failure rates, latency, and SLA compliance
“Netflix’s data pipeline platform handles over 500 billion events per day, powered by scalable Spark-based ETL and metadata-first workflows.”
Design Smarter: Proven Patterns for Scalable ETL Pipeline Architecture
Scaling ETL pipelines requires purposeful design patterns that ensure resilience, maintainability, and growth-readiness:
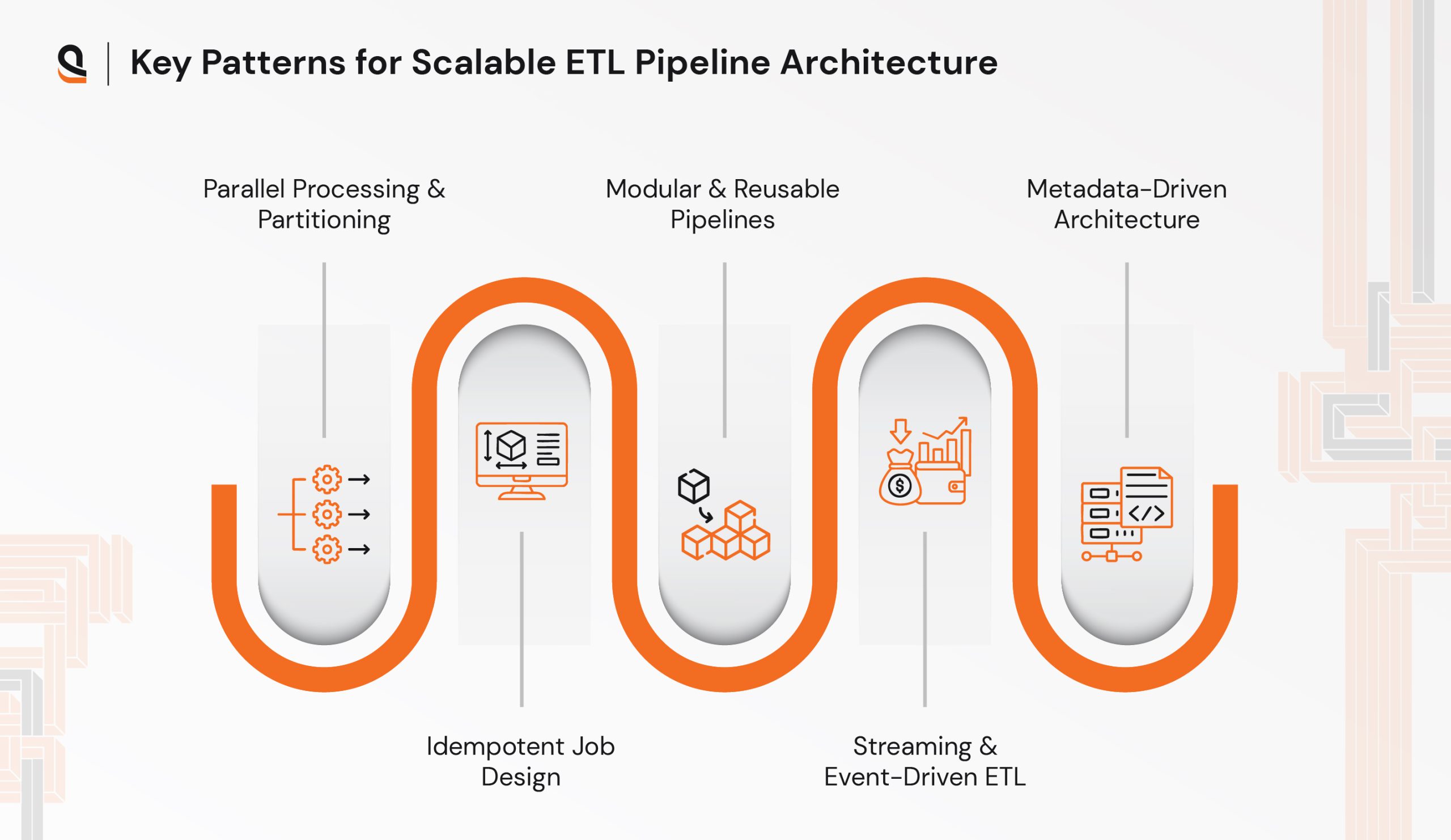
Parallel Processing & Partitioning
- Splits large datasets into manageable chunks by time window, geography, or category
- Enables multi-threaded or distributed ETL execution
Idempotent Job Design
- Ensures reprocessing data doesn’t create duplicates or corrupt datasets
- Especially critical in retry or failure-recovery scenarios
Modular & Reusable Pipelines
- Break pipelines into micro-jobs (ingest, transform, load) for easy debugging and reusability
- Promotes CI/CD practices in data workflows
Streaming & Event-Driven ETL
- Instead of scheduled batch jobs, streaming ETL reacts to events (new row added, file uploaded)
- Tools like Kafka Streams, Apache Flink, or AWS Kinesis enable this low-latency pattern
Metadata-Driven Architecture
- Automates ETL behavior based on source metadata (e.g., table structure, data types, volume stats)
- Enhances governance, data lineage, and auditing
Enterprise-Ready ETL Architecture in Action
A well-architected ETL pipeline can scale from handling 10,000 records per day to processing billions in near real time. Here’s how it supports key enterprise needs:
| Enterprise Requirement | Architectural Response |
| High availability | Clustered pipeline runtimes, failover mechanisms |
| Governance & compliance | Role-based access, data masking, lineage tracking |
| Cross-environment support | CI/CD-ready deployments, containerization (Docker, Kubernetes) |
| Real-time insights | Hybrid streaming+batch design, message queuing |
| Data observability | Integrated metrics, alerts, data quality checks (e.g., Great Expectations) |
ETL Pipeline Optimization Techniques That Actually Work
As your business grows, your data grows with it. But more data doesn’t have to mean slower processes, higher cloud bills, or unreliable analytics. This is where ETL pipeline optimization techniques come in—they help make your data pipelines faster, more cost-effective, and easier to maintain. Let’s walk through these strategies in a business-friendly and results-driven way.
Performance Boosts Through Smart Design
When it comes to performance, how your pipeline is structured has a massive impact on how well it runs.
Use Parallelism and Partitioning
Think of your data like a stack of paperwork. If one person handles it, it takes time. But if 10 people handle 10 parts at once, it’s much faster.
- Parallelism breaks your ETL jobs into smaller chunks that can run simultaneously.
- Partitioning organizes your data by fields like time, location, or region, so only the needed segment is processed at a time.
Business Benefit: Reduces ETL job run time by up to 40–60% and speeds up report delivery to decision-makers.
Leverage In-Memory Processing
- Instead of saving every intermediate step to disk (which is slow), modern ETL tools process data in memory (RAM). Tools like Apache Spark are built for this. Think of this like cooking without putting each ingredient in the fridge after cutting it—you move faster.
Business Benefit: Helps process larger datasets faster, enabling near real-time analytics.
Push-Down Optimization
- This means doing as much of the transformation as possible where the data lives (like inside a database), rather than moving it around unnecessarily. For example, let your database filter or join tables before sending data to the ETL tool.
Business Benefit: Saves both time and bandwidth; reduces costs on cloud resources.
Load-Time Improvements
Loading is the final stage of an ETL pipeline—and also a major performance bottleneck if not handled correctly.
Choose Between CDC and Full Refresh Wisely
Full refresh means replacing your entire dataset every time. Simple, but inefficient for large data. CDC (Change Data Capture) only updates records that have changed since the last load. Use CDC if:
- Your source system supports it (many modern databases do)
- You deal with large, growing datasets
Business Benefit: Reduces data volume processed daily by 70–90%, saving compute time and storage.
Tune Batch Sizes & Use Buffers
Instead of loading row-by-row (very slow), load in batches (groups). The size of these batches matters: too small, it’s slow; too large, it risks failure or timeout. Smart buffering prevents sudden spikes and makes processing smoother.
Business Benefit: Keeps pipelines steady and reduces failure rates during large-volume transfers.
Cost Optimization
Enterprise data platforms can get expensive—especially when pipelines are inefficient. Let’s fix that.
Minimize Compute Time in Cloud ETL Platforms
Most cloud ETL services (like AWS Glue or Dataflow) charge by the minute or by resources used. So reducing runtime directly lowers your bill.
- Use auto-scaling and ephemeral compute (pay only when used)
- Shut down idle resources between jobs
Business Benefit: Lowers monthly cloud costs without compromising data delivery.
Smart Scheduling & Off-Peak Processing
Run heavy ETL jobs during off-peak hours when cloud resources are cheaper and business users are less active. For example, schedule large nightly jobs at 2 AM instead of 6 AM.
Business Benefit: Some companies report 20–30% lower cloud costs just by optimizing job schedules.
Governance & Efficiency
Beyond performance and cost, trust in your data pipeline is essential. Optimization isn’t just about speed—it’s about doing things reliably and transparently.
Build Observability Into the Pipeline (Not Around It)
Add monitoring at each step—know how long each task takes, where it fails, and how much data it processes. Tools like Airflow, Dagster, or Monte Carlo help visualize this.
Business Benefit: Helps proactively fix issues before they impact business dashboards or operations.
Track SLAs, Data Contracts, and Drift
- SLAs: Define how fast data should be available.
- Data contracts: Agreements between systems on data format/quality.
- Drift: When data changes unexpectedly (e.g., a new column appears or a format changes).
Monitoring for these avoids surprises and broken reports.
Business Benefit: Prevents bad data from reaching stakeholders, saving time, money, and credibility.
| Optimization Focus | Key Technique | Enterprise Advantage |
| Performance | Parallelism & in-memory | Faster job execution |
| Reliability | Idempotent loads & observability | Fewer errors & more transparency |
| Cost | Smart scheduling & resource scaling | Lower cloud bills |
| Data Trust | Data contracts & drift detection | Better decision-making confidence |
Optimization isn’t about one-time tweaks—it’s a culture of continuous improvement. By embedding these techniques into your data engineering playbook, your ETL pipelines become faster, leaner, and more aligned with business needs.
4 Best Practices for Building ETL Pipelines in Enterprises

Building scalable and resilient ETL pipelines in an enterprise setting is not just about processing data—it’s about ensuring that data is reliable, secure, and delivered consistently. The following ETL pipeline best practices will help you create data flows that are not only efficient, but also easier to manage and evolve as your business grows.
Plan for Failure: Build with Resilience in Mind
In the real world, failures happen—servers crash, networks drop, files get corrupted. Your ETL pipeline should be built assuming that something will go wrong at some point. How to plan for failure:
- Retries: Configure automatic retries for failed tasks to avoid manual intervention.
- Checkpoints: Save pipeline progress periodically so you can resume without starting over.
- Idempotency: Design your transformations and loads in a way that running them multiple times doesn’t produce duplicates or errors.
Modular Pipeline Development: Keep It Clean and Reusable
Rather than building a long, complex ETL workflow in one piece, break it into smaller, self-contained modules (e.g., ingest, transform, load). Why modularity matters:
- Easier debugging: If one part fails, it’s easier to isolate and fix.
- Reusability: You can reuse common modules (e.g., email extraction, address standardization) across different pipelines.
- Better version control: You can update parts of the pipeline without touching the whole system.
Use Shared Transformation Libraries to Avoid Redundancy
Rewriting the same transformation logic (like currency conversion or date formatting) in multiple pipelines leads to inconsistencies and bugs. Instead:
- Create and maintain a central library of transformation functions or scripts.
- Use versioned packages or containerized utilities so that all pipelines use the same logic base.
Benefits:
- Ensures consistency across datasets
- Saves engineering time
- Reduces duplication and long-term maintenance headaches
Secure Your Pipelines from Source to Destination
Enterprise ETL pipelines handle sensitive and valuable data—customer records, financial transactions, healthcare logs, and more. Security cannot be an afterthought. Key security practices:
- Data masking: Hide sensitive fields (e.g., credit card numbers) in non-production environments.
- Encryption: Use encryption at rest and in transit to protect data from breaches.
- Access controls: Implement role-based access so only authorized users can view or manipulate data flows.
- Compliance-ready pipelines: These practices also help you meet regulations like GDPR, HIPAA, SOC 2, etc.
Combining these best practices gives your ETL pipelines the backbone to scale, adapt, and thrive in dynamic enterprise environments. You’re not just moving data—you’re building trust in the information your business runs on.
Emerging Trends in ETL and Enterprise Data Engineering
Enterprises today are evolving their data architecture rapidly, embracing powerful new trends that reshape how ETL data pipelines are designed and deployed. Here’s a deep dive into the key trends—no-code ETL, data mesh & data products, and serverless/zero‑ETL—and how they’re transforming enterprise data strategies.
The Rise of No‑Code ETL Platforms
No-code and low-code ETL platforms allow users to build data pipelines via intuitive, drag-and-drop interfaces—no deep programming skills required. This democratization shifts power toward “citizen integrators” in line-of-business teams and significantly accelerates time-to-insight.
- USD 65 billion is the forecasted size of the no-code/low-code market by 2027, rising sharply from USD 26.9 billion in 2023.
- By 2025, 70% of new enterprise applications will be built with no-code or low-code platforms .
- Large organizations are adopting them widely: 75% of large enterprises use at least four no/low-code tools
- These platforms can cut development time by up to 70% and deliver significant ROI—509% over five years.
Benefits for enterprises:
- Non-IT users can quickly create pipelines for reporting, marketing data consolidation, proof-of-concept projects.
- Frees up engineering teams to focus on complex integrations and heavyweight data solutions.
- Enables rapid prototyping and faster iteration cycles.
ETL in the Context of Data Mesh and Data Products
The data mesh paradigm is gaining traction, treating data as a product managed by cross-functional teams. Instead of centralized pipelines, each domain owns its data product with embedded ETL workflows. So, here is why this matters:
- Each team builds, operates, and scales its own pipelines for its data domain.
- Promotes ownership, clear data contracts, and reliable cross-domain sharing.
Connections to ETL:
- Pipelines produce domain-specific ETL outputs—cleansed, aggregated, governed—for other teams to consume.
- Automated transformation logic embeds data contracts to ensure quality and interoperability.
This shift fosters a more agile enterprise where ETL is not a siloed technical process but part of a decentralized data ecosystem.
Serverless ETL Pipelines and Zero‑ETL
Serverless ETL lets organizations run data pipelines without managing servers—scaling automatically and charging only for used resources. Companies like Netflix use AWS Lambda for ETL, processing billions of events daily. Serverless ETL supports real-time transformation, enabling instant analytics on streaming data.
Zero‑ETL, another emerging approach, minimizes user-managed pipelines by auto-syncing data between systems (e.g., SaaS to warehouse), or performing transformations inside the destination platform. It reduces maintenance burden and operational overhead. However, zero-ETL may not suit enterprises needing custom logic, data masking, or complex schema transformations.
Key Takeaway for Enterprises
| Trend | Impact | Best Use Cases |
| No-code ETL | Democratizes pipeline creation; faster time-to-value | Non-technical teams, POCs, marketing/finance use cases |
| Data mesh + ETL | Enables domain-owned data products and governance | Large-scale enterprises needing domain autonomy and data contracts |
| Serverless/Zero‑ETL | Reduces ops overhead; minimizes infrastructure maintenance | Event-driven pipelines, real-time analytics, SaaS integrations |
Wrapping Up
The evolution of data in the enterprise is accelerating—faster sources, deeper analytics, tighter governance. Building scalable ETL data pipelines is no longer just about moving data from point A to B. It’s about designing systems that adapt to growth, integrate seamlessly with modern platforms, and enable your teams to make decisions with confidence.
From defining the right ETL pipeline architecture, to choosing tools that match your needs, to applying proven optimization techniques, the path to efficiency and resilience lies in making thoughtful, future-ready decisions. Whether you’re exploring no-code platforms, modular microservices, or real-time streaming pipelines, the ultimate goal remains the same: delivering the right data to the right people, at the right time.
At AQe Digital, we’ve helped organizations with our data analytics consulting services to foster businesses reimagine their data infrastructure—from modernizing legacy ETL workflows to deploying intelligent, scalable data pipelines that power analytics, AI, and automation. If you’re considering building or refining your own ETL ecosystem, we’d be glad to explore how we can support your journey.
